
GNN(图神经网络)的调研的任务。
搜索相关的文献
确定相关的关键词
- GIN
- Graphormer
Graphormer
最早提出论文:
Do Transformers Really Perform Bad for Graph Representation?
作者:Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu
作者提出了Graphormer,这是一个基于标准Transformer架构的模型,在广泛的图表示学习任务上都取得了出色的结果。在图中使用Transformer的关键见解是需要有效地将图的结构信息编码到模型中。为此,作者提出了几种简单但有效的结构编码方法,以帮助Graphormer更好地建模图结构数据¹。
(2021)
被引用次数:未知
NeurIPS
摘要:Transformer架构已经成为许多领域的主导选择,例如自然语言处理和计算机视觉。然而,与主流的GNN变体相比,它在图级预测的流行排行榜上还没有取得竞争性的表现。因此,Transformers如何在图表示学习上表现良好仍然是一个谜。在这篇论文中,我们通过提出Graphormer来解决这个谜团,它是基于标准Transformer架构构建的,并且可以在广泛的图表示学习任务上取得出色的结果,尤其是在最近的OGB大规模挑战上。我们在图中使用Transformer的关键见解是需要有效地将图的结构信息编码到模型中。为此,我们提出了几种简单但有效的结构编码方法,以帮助Graphormer更好地建模图结构数据¹。
[PDF链接](https://arxiv.org/abs/2106.05234
[GitHub仓库链接](microsoft/Graphormer: Graphormer is a general-purpose deep learning backbone for molecular modeling. (github.com))
前置说明:
OGB Large-Scale Challengel:
Open Graph Benchmark (OGB) Large-Scale Challenge (OGB-LSC) 是一个大规模的图机器学习挑战。以下是关于这个挑战的总结:
背景:图机器学习(Graph ML)在近年来受到了巨大的关注,因为在现实世界的应用中,图结构数据非常普遍。这些应用领域包括大规模的社交网络、推荐系统、超链接的网络文档、知识图谱,以及由不断增长的科学计算产生的分子模拟数据。但是,大多数图ML模型都是在非常小的数据集上开发和评估的。
挑战:处理大规模图是具有挑战性的,特别是对于最先进的图神经网络(GNNs),因为它们基于其他许多节点的信息对每个节点进行预测。近期,研究者们通过大大简化GNNs来提高模型的可扩展性,但这不可避免地限制了它们的表达能力。
OGB-LSC的目标:鼓励为大型现代数据集开发最先进的图ML模型。特别是,提供了三个数据集:MAG240M、WikiKG90M和PCQM4M,这些数据集在规模上都是前所未有的大,并分别涵盖了节点、链接和图的预测。
数据集概览:
- MAG240M:一个异构的学术图,任务是预测位于异构图中的论文的主题领域(节点分类)。
- WikiKG90M:一个知识图,任务是补全缺失的三元组(链接预测)。
- PCQM4M:一个量子化学数据集,任务是预测给定分子的一个重要的分子属性,即HOMO-LUMO差距(图回归)。
工具和资源:所有这些数据集都可以使用ogb Python包下载和准备。模型评估和测试提交文件的准备也由该包处理。
目标:鼓励社区开发和扩展表达性强的图ML模型,这可以在各自的领域中取得重大突破。希望OGB-LSC在KDD Cup 2021上能够像“ImageNet大规模视觉识别挑战”那样在图ML领域起到推动作用。
团队和联系:OGB-LSC团队由来自斯坦福大学、TU Dortmund、RIKEN和Facebook AI的研究者组成。他们可以通过电子邮件或GitHub进行联系。
合作伙伴:Intel公司的Amit Bleiweiss和Benjamin Braun。
GNN(图神经网络):
GNN可以被抽象为Aggregate和Combine两个步骤。公式中 $\mathrm{h}$ 代表各个层中某个节点的隐向量,a 表示 某个节点 $\mathrm{i}$ 对于他的邻居 $\mathrm{j}$ 们,通过某个聚合函数aggregate获得的信息。通过某个函数将(l-1)层的隐向量和 (1)层的信息combine,就能够获得(1)层的隐向量。
$$
a_i^{(l)}=\operatorname{AGGREGATE}^{(l)}\left(\left{h_j^{(l-1)}: j \in \mathcal{N}\left(v_i\right)\right}\right), \quad \h_i^{(l)}=\operatorname{COMBINE}^{(l)}\left(h_i^{(l-1)}, a_i^{(l)}\right),
$$
此外,用一个图读出(Readout)函数来将很多节点的隐向量表征为一个统一长度的向量表示。
$$
h_G=\operatorname{READOUT}\left(\left{h_i^{(L)} \mid v_i \in G\right}\right) .
$$
在图论和网络科学中,节点的度是与其相连的边的数量。在有向图中,节点的度可以进一步分为入度和出度:
- 入度($\text{deg}^+(v_i) $):指向节点 $ v_i $ 的边的数量。简单地说,这是有多少其他节点“指向”这个节点的数量。
- 出度($ \text{deg}^-(v_i) $):从节点 $v_i $ 指出的边的数量。这表示节点 $ v_i $ 指向其他节点的边的数量。
例如,考虑一个社交网络中的用户和他们之间的关注关系。如果 Alice 关注了 5 个人,那么 Alice 的出度是 5。如果有 3 个人关注了 Alice,那么 Alice 的入度是 3。
使用度中心性(degree centrality)来为每个节点分配嵌入向量。这种方法考虑了节点的入度和出度,并为每个节点分配两个嵌入向量 $ z^+ $ 和 $ z^- $。这些嵌入向量可以进一步与节点的原始特征相结合,以提供更丰富的节点表示。
这种方法的一个潜在好处是,它可以帮助捕捉到网络中节点的重要性或中心性。具有高入度的节点可能是网络中的权威或受欢迎的节点,而具有高出度的节点可能是广泛连接或传播信息的节点。
论文阅读
背景与动机:
- Transformer 架构在许多领域,如自然语言处理和计算机视觉中,已经成为了主导选择。但在图级预测的流行排行榜上,它还没有达到与主流 GNN 变体相媲美的性能。这引发了一个问题:Transformer 架构是否真的适合图表示学习?
Graphormer 的提出:
- 为了解决上述问题,作者提出了 Graphormer。这是一个基于标准 Transformer 架构的模型,但进行了特定的修改,使其能够更好地处理图数据。
结构编码的重要性:
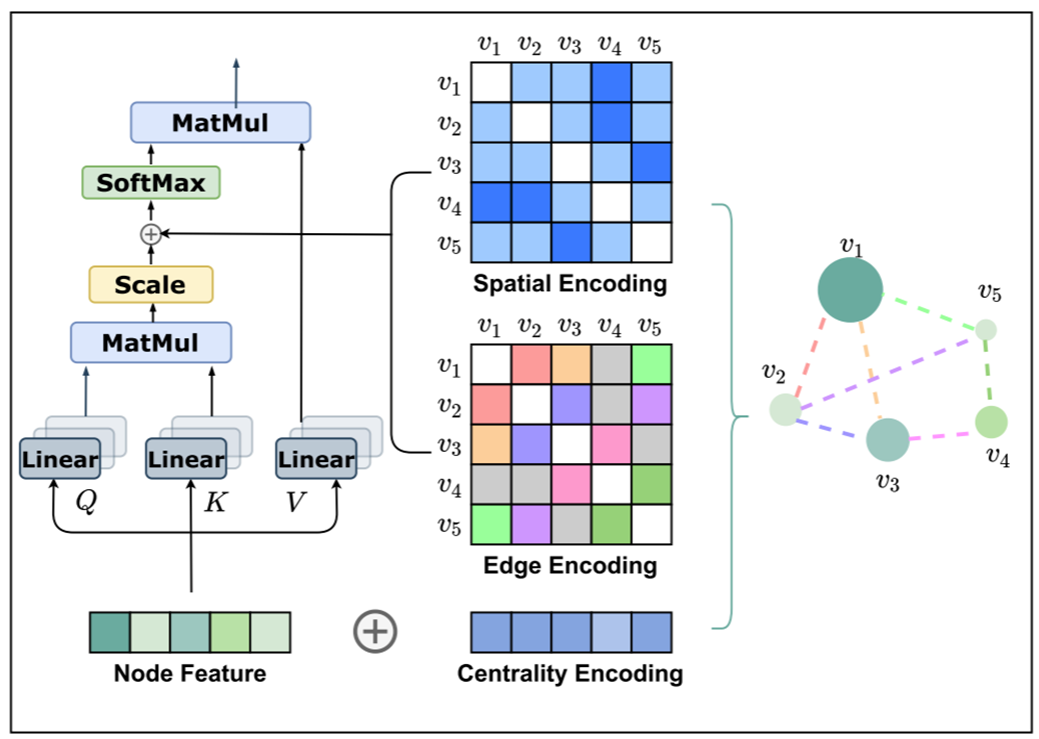
作者认为,要使 Transformer 在图上表现得更好,关键是要正确地将图的结构信息纳入模型中。为此,他们提出了三种结构编码方法:
- 中心性编码。使用度中心性 (degree centrality),根据入度 $\operatorname{deg}^{+}\left(\mathrm{v}{\mathrm{i}}\right)$ 和出度 $\operatorname{deg}^{-}\left(\mathrm{v}{\mathrm{i}}\right)$ 给每个节点分配两个嵌 入向量 $z^{+}, z^{-} \in \mathrm{R}^{\mathrm{d}}$ ,将它们加到节点特征上。
$$
h_i^{(0)}=x_i+z_{\operatorname{deg}^{-}\left(v_i\right)}^{-}+z_{\operatorname{deg}^{+}\left(v_i\right)}^{+}
$$- 空间编码。用函数 $\varphi\left(v_{\mathrm{i}}, \mathrm{v}{\mathrm{j}}\right): \mathrm{V} \times \mathrm{V} \rightarrow \mathrm{R}$ 来衡量 $\mathrm{v}{\mathrm{i}}, \mathrm{v}{\mathrm{i}}$ 之间的最短路径距离(SPD),以 $\varphi\left(\mathrm{v}{\mathrm{i}}, \mathrm{v}{\mathrm{j}}\right)$ 为索引得到 可学习的标量 $b{\varphi\left(v_i, v_j\right)}$ ,然后将其作为偏置项加到注意力矩阵A中。
$$
A_{i j}=\frac{\left(h_i W_Q\right)\left(h_j W_K\right)^T}{\sqrt{d}}+b_{\phi\left(v_i, v_j\right)}
$$- 边编码。找到从 $\mathrm{v}{\mathrm{i}}$ 到 $\mathrm{v}{\mathrm{j}}$ 的最短路径 $\mathrm{SP}_{\mathrm{ij}}=\left(\mathrm{e}1, \mathrm{e}2, \ldots, \mathrm{e}{\mathrm{N}}\right)$ ,计算边特征 $x{e_n}$ 与可学习嵌入 $w_n^E$ 的点积的平均 值,作为偏置项加到注意力模块中。
$$
A_{i j}=\frac{\left(h_i W_Q\right)\left(h_j W_K\right)^T}{\sqrt{d}}+b_{\phi\left(v_i, v_j\right)}+c_{i j} \text {, where } c_{i j}=\frac{1}{N} \sum_{n=1}^N x_{e_n}\left(w_n^E\right)^T \text {, }
$$
实验结果与分析:
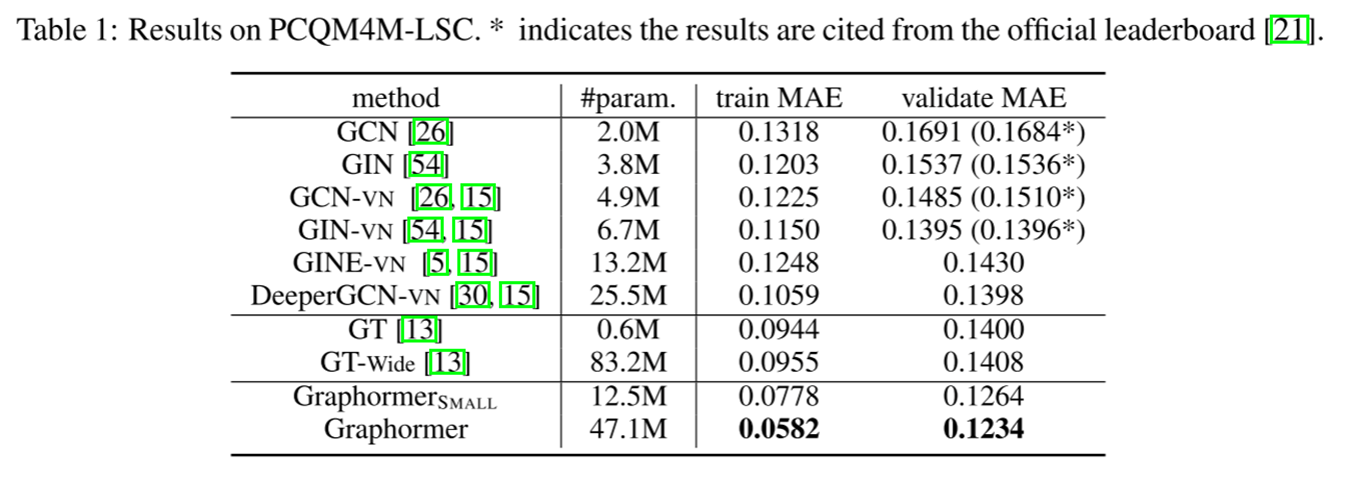
- Graphormer 在多个图表示学习任务上都表现出色。特别是在最近的 OGB 大规模挑战上,Graphormer 的性能超过了大多数主流 GNN 变体。
- 作者还从理论上证明了 Graphormer 的强大表达能力,表明许多流行的 GNN 变体都可以被视为 Graphormer 的特殊情况。
baseline模型总结
| 模型 | 说明 | 参考文献 |
|---|---|---|
| GCN | 经典的图神经网络模型 | [26] |
| GIN | 流行的图神经网络模型 | [54] |
| GCN-VN | GCN的虚拟节点版本 | [15] |
| GIN-VN | GIN的虚拟节点版本 | [15] |
| GIN的多跳变体 | 考虑了多跳的信息的GIN变种 | [5] |
| DeeperGCN | 12层深的图神经网络模型 | [30] |
| GT | 基于Transformer的图模型 | [13] |
| Graphormer | 作者提出的模型,大小为(L = 12, d = 768) | - |
| GraphormerS MALL | 作者提出的较小版本模型,大小为(L = 6, d = 512) | - |
数据集及任务
| 数据集 | 说明 | 任务 | 参考链接 |
|---|---|---|---|
| PCQM4M-LSC | 来自OGB Large-Scale Challenge的量子化学回归数据集,包含超过3.8M的图。 | 回归 | OGB-LSC |
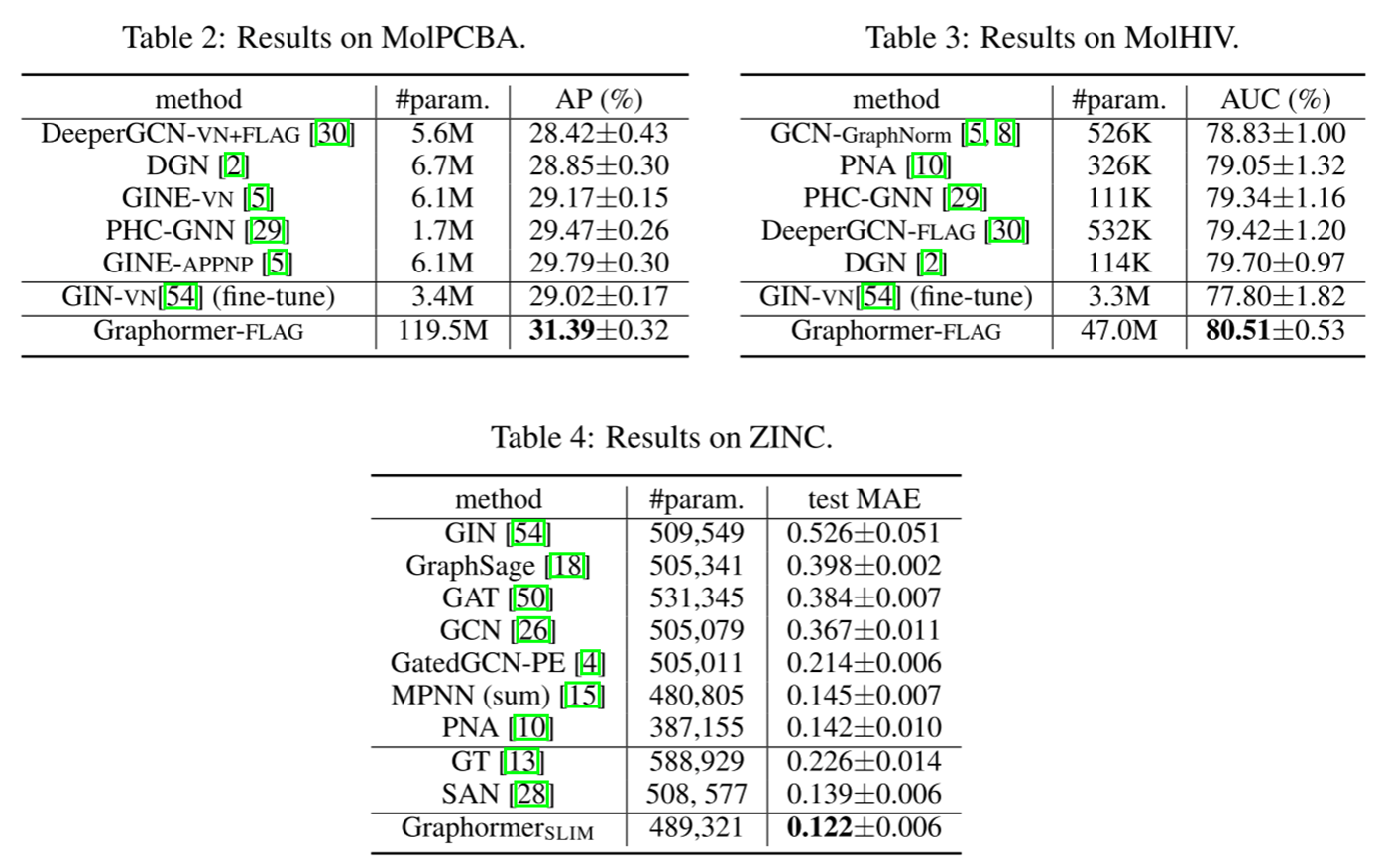
| OGBG-MolPCBA | OGB的一个数据集,用于分子预测。 | 二元分类 | OGB |
| OGBG-MolHIV | OGB的一个数据集,用于HIV活性预测。 | 二元分类 | OGB |
| ZINC (sub-set) | 一个用于分子属性预测的数据集的子集。 | 回归 | - |
本文总结
Transformer 的适应性:
- 这篇论文进一步证明了 Transformer 架构的灵活性和适应性。尽管它最初是为序列数据设计的,但通过适当的修改和编码,它可以成功地应用于图数据。
结构编码的深入分析:
传统的 Transformer 模型可能无法捕获图数据的复杂性。这是因为图数据的结构信息与序列数据或图像数据不同。通过引入结构编码,Graphormer 能够更好地理解和表示图结构数据。
事实1:这一事实表明Graphormer可以代表流行GNN模型的AGGREGATE和COMBINE步骤。证明基于空间编码,该编码允许模型区分不同的节点及其邻居。
超越经典的GNN:借助其空间编码,Graphormer可以超越传统GNN的表达能力。它可以区分Weisfeiler-Lehman测试无法区分的图。
自注意与虚拟节点之间的联系:文本强调了自注意机制与虚拟节点启发式之间的联系。虚拟节点技巧通过添加超节点来提高GNN的性能。但是,得益于其自注意机制,Graphormer可以在不需要这些超节点的情况下实现类似的效果。
事实2:这一事实强调了Graphormer中的自注意机制允许每个节点关注所有其他节点,从而模拟图级READOUT操作。这避免了其他方法中出现的过度平滑问题。
思考和理解:
通过transformer的编码处理, 可以让传统
GNN的表示能力更强,能够表示并区分传统GNN无法区分和表示的内容, 常见的GNN都属于其变体。
GIN
[**How Powerful Are Graph Neural Networks?**](1810.00826.pdf (arxiv.org))
作者:Keyulu Xu, Weihua Hu, Jure Leskovec, Stefanie Jegelka
发布日期:(2019)
来源:ICLR 2019
摘要:
图神经网络 (GNNs) 是一种有效的图表示学习框架。GNNs 采用邻域聚合策略,通过递归地聚合和转换其邻域节点的表示向量来计算节点的表示向量。尽管许多 GNN 变体已经被提出并在节点和图分类任务上取得了最先进的结果,但对于 GNNs 的表示属性和局限性的理解仍然有限。本文提出了一个理论框架,用于分析 GNNs 捕获不同图结构的表达能力。结果表明,流行的 GNN 变体,如图卷积网络和 GraphSAGE,不能学习区分某些简单的图结构。然后,我们开发了一个简单的架构,它在 GNNs 类中具有最大的表达能力,并与 Weisfeiler-Lehman 图同构测试一样强大。我们在多个图分类基准上验证了我们的理论发现,并证明了我们的模型达到了最先进的性能。
前置说明:
WeisfeilerLehman图同构检验:
许多不同的图神经网络变体已经被提出,这些变体具有不同的邻域聚合和图级池化方案。
图神经网络常见任务分类:
节点分类 (Node Classification):
- 定义:在图中,每个节点可能代表一个实体,节点分类的任务是为每个节点分配一个或多个类别标签。
- 应用示例:在社交网络中,节点可能代表个人,而节点分类的任务可能是预测每个人的兴趣或职业。
- 方法:GNNs通过聚合一个节点的邻居信息来学习节点的表示,这有助于预测节点的类别。
链接预测 (Link Prediction):
- 定义:链接预测的任务是预测图中是否应该存在两个节点之间的边。
- 应用示例:在推荐系统中,节点可能代表用户和物品,而链接预测的任务是预测用户是否会对某个物品感兴趣(即是否应该在用户和物品之间存在一个“链接”)。
- 方法:GNNs可以学习节点对之间的相似性或关系,从而预测它们之间是否应该有链接。
图分类 (Graph Classification):
- 定义:在这个任务中,整个图被赋予一个标签。与节点分类不同,图分类关注的是整个图的属性,而不仅仅是单个节点。
- 应用示例:在化学中,每个图可能代表一个分子,而图分类的任务可能是预测分子的某些属性,如它是否有毒。
- 方法:GNNs可以学习整个图的表示,通常通过池化所有节点的表示来实现,然后使用这个表示来预测图的类别。
-
WL测试的优势:WL测试的主要优势在于它的”单射聚合更新”能力,这使得它可以将不同的节点邻域映射到不同的特征向量。
- 同构的定义:
关于GNN的关键见解:如果一个GNN的聚合方式足够强大并能模拟单射函数,那么这个GNN就可以达到与WL测试相同的区分能力。
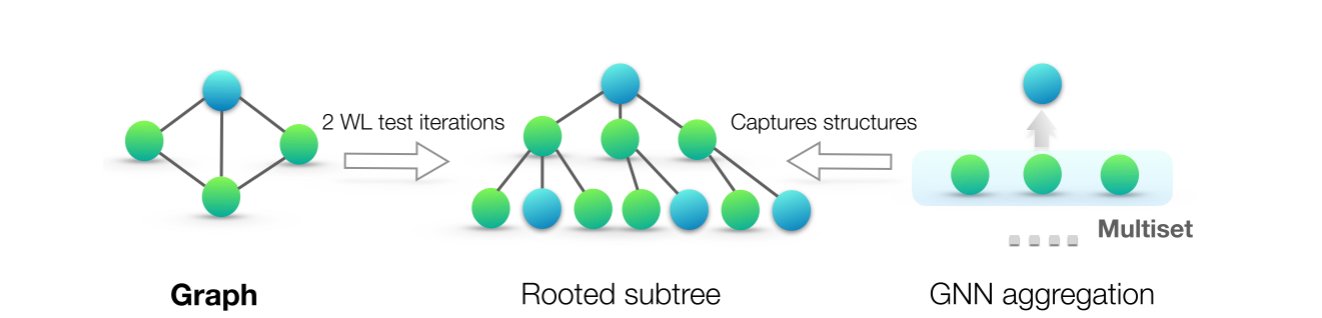
首先将给定节点的邻居的特征向量表示为一个多重集,即可能有重复元素的集合。然后,GNN中的邻居聚合可以被认为是对多重集的一个聚合函数。因此,为了具有强大的表示能力,GNN必须能够将不同的多重集聚合成不同的表示。
- AGGERATE, 汇聚:(GraphSAGE)
$$
a_v^{(k)}=\operatorname{MAX}\left(\left{\operatorname{ReLU}\left(W \cdot h_u^{(k-1)}\right), \forall u \in \mathcal{N}(v)\right}\right)
$$
- 对于节点 $\mathrm{v}$ 的每个邻居 $\mathrm{u}$ ,我们首先取其在第 $\mathrm{k}-1$ 轮的特征向量 $h_u^{(k-1)}$ 。
- 然后,我们使用权重矩阵W对这个特征向量进行线性变换,并应用ReLU激活函数。
- 最后,我们从所有邻居 $\mathrm{u}$ 得到的值中取最大值,得到节点 $\mathrm{v}$ 在第 $\mathrm{k}$ 轮的聚合特征 $a_v^{(k)}$ 。
这种操作可以被视为一种特殊的邻居信息聚合策略,其中节点 $v$ 在第 $k$ 轮的特征是基于其所有 邻居在第 $k-1$ 轮的特征的最大激活值得到的。
- AGGREGATE and COMBINE 步骤综合在一起(GCN, 图卷积神经网络):
$$
h_v^{(k)}=\operatorname{ReLU}\left(W \cdot \operatorname{MEAN}\left{h_u^{(k-1)}, \forall u \in \mathcal{N}(v) \cup{v}\right}\right) .
$$
- 对于节点 $\mathrm{v}$ ,我们考虑其所有邻居 $\mathrm{u}$ 的特征向量 $h_u^{(k-1)}$ ,以及节点 $\mathrm{v}$ 自己在第 $\mathrm{k}-$ 轮的特征向 量。
- 接着,我们计算这些特征向量的平均值。这是通过MEAN操作完成的。
- 然后,我们使用权重矩阵W对这个平均值进行线性变换,并应用ReLU激活函数。
- 最后,得到的结果是节点 $\mathrm{v}$ 在第 $\mathrm{k}$ 轮的特征向量 $h_v^{(k)}$ 。
这种操作是一种邻居信息聚合策略,其中节点 $v$ 在第 $k$ 轮的特征是基于其所有邻居以及其自身 在第 $k-1$ 轮的特征的平均值得到的。这种策略有助于捕捉节点 $v 及$ 其邻居的整体特征或模式。How Powerful Are Graph Neural Networks?:
背景:图结构数据的学习,如分子、社交、生物和金融网络,需要有效地表示其图结构。近年来,图神经网络 (GNN) 在图的表示学习中引起了广泛的关注。
主要贡献:本文提出了一个理论框架,用于分析 GNNs 的表达能力,以捕获和区分不同的图结构。
方法:该方法受到 GNNs 和 Weisfeiler-Lehman (WL) 图同构测试之间的紧密联系的启发。与 GNNs 类似,WL 测试通过聚合节点及其网络邻居的特征向量来迭代地更新给定节点的特征向量。
实验:作者在图分类数据集上验证了他们的理论,其中 GNNs 的表达能力对于捕获图结构至关重要。实验结果证实,从理论上讲,最强大的 GNN,即图同构网络 (GIN),在实践中也具有高度的表示能力。
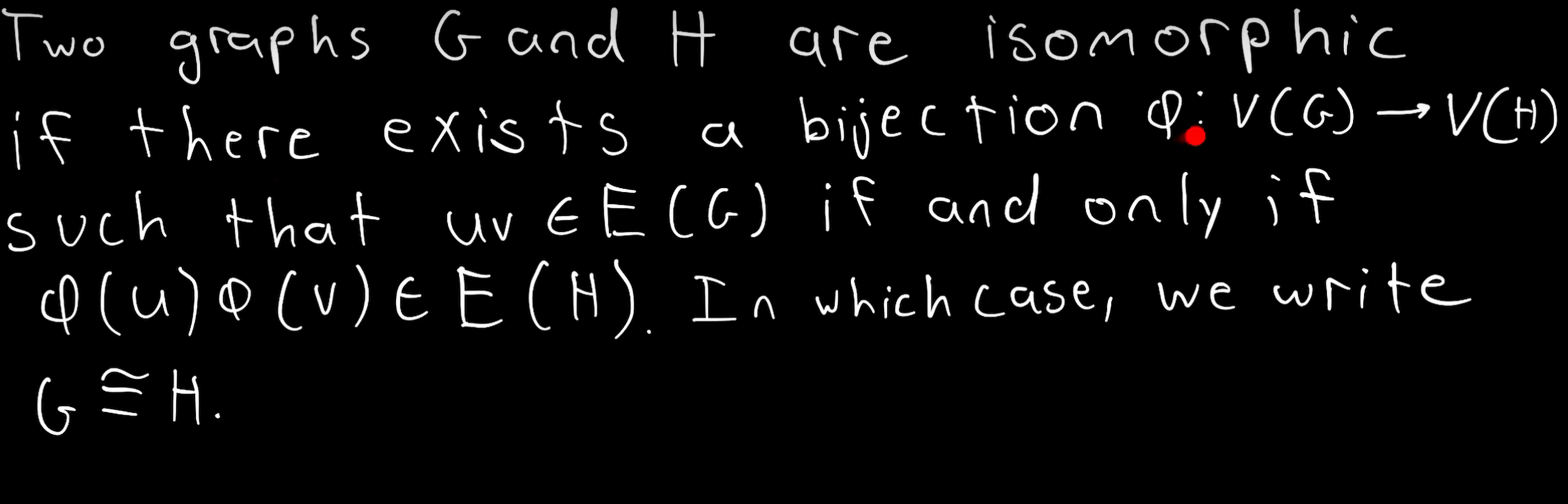
论文阅读
背景与动机:
- 图神经网络 (GNNs) 是图表示学习的有效框架。GNNs 采用邻域聚合方案,通过递归地聚合和转换其邻近节点的表示向量来计算节点的表示向量。尽管许多 GNN 变体已经被提出并在节点和图分类任务上取得了最先进的结果,但对于 GNNs 的表示属性和局限性的理解仍然有限。本文提出了一个理论框架,用于分析 GNNs 捕获不同图结构的表现力。
模型网络框架:
结构与编码:
- 作者首先将给定节点的邻居的特征向量集表示为多集,即可能重复元素的集合。然后,GNNs 中的邻居聚合可以被认为是一个多集上的聚合函数。为了具有强大的表示能力,GNN 必须能够将不同的多集聚合为不同的表示。
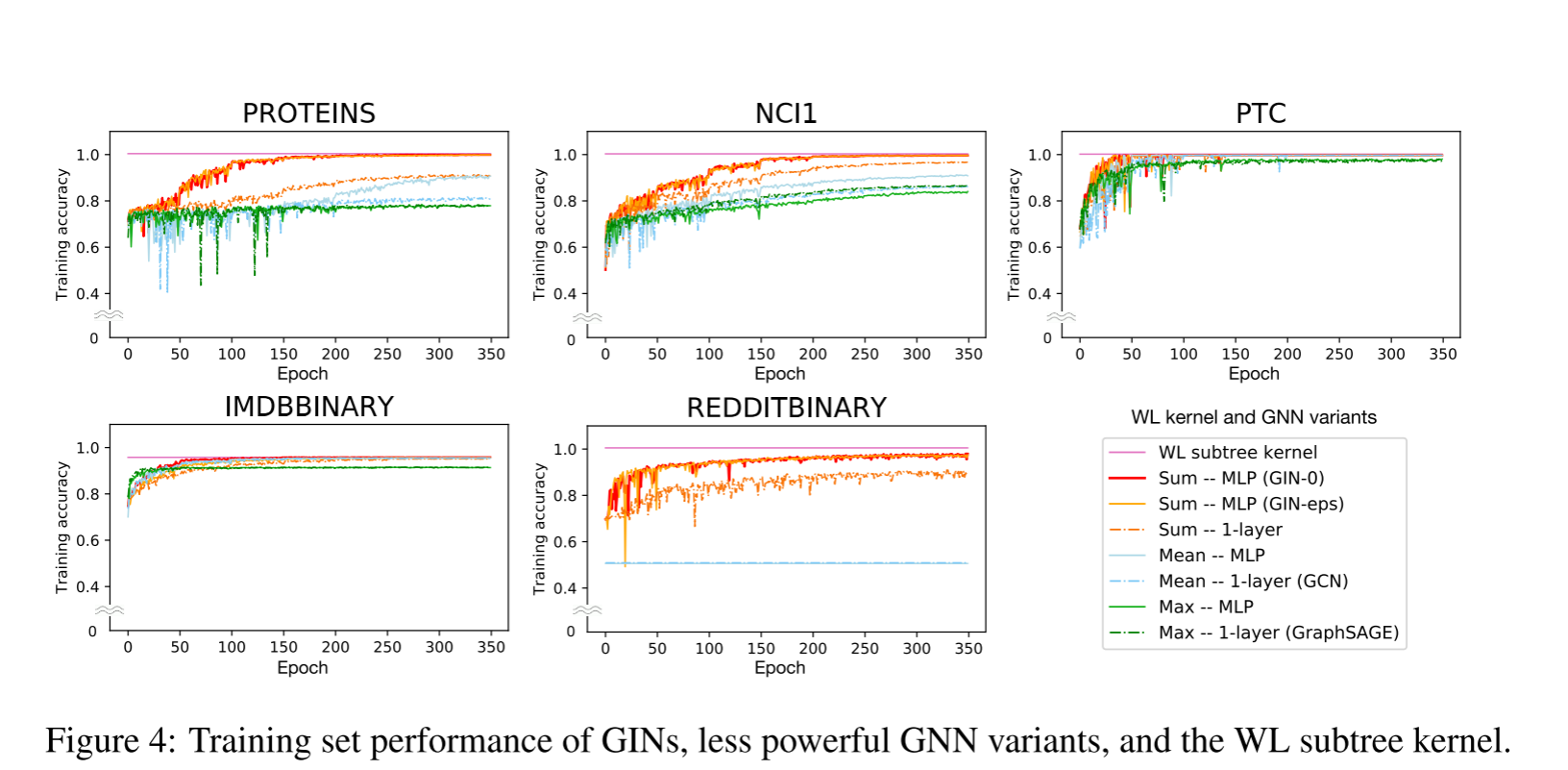
实验结果与分析:
实验部分笔记:
- 目的:
- 评估和比较图同构网络(GIN)及其其他图神经网络(GNN)变体的训练和测试性能。
- 数据集:
- 使用了9个图分类基准。
- 包括4个生物信息学数据集:MUTAG、PTC、NCI1、PROTEINS。
- 5个社交网络数据集:COLLAB、IMDB-BINARY、IMDB-MULTI、REDDIT-BINARY、REDDIT-MULTI5K。
- 主要目标是从网络结构中学习,而不是依赖于输入节点特征。
- 模型配置:
- 评估了 GINs 和其他较弱的 GNN 变体。
- GIN 有两个变体:GIN-ε(通过梯度下降学习)和 GIN-0(ε固定为0)。
- 对于其他 GNN 变体,考虑了替换聚合中的求和为平均或最大池化,或用1层感知器替换多层感知器。
- 评估方法:
- 使用10折交叉验证。
- 使用了 LIB-SVM 进行验证。
- 报告了10折交叉验证中的平均验证准确性和标准差。
- 实验设置:
- 所有配置都应用了5个 GNN 层。
- 所有多层感知器(MLPs)有2层。
- 使用 Adam 优化器,初始学习率为0.01。
- 超参数包括隐藏单元数、批大小、dropout 比率和时代数。
- 基线比较:
- 使用了其他的图分类方法作为基线进行比较。
- 包括 WL 子树核、扩散-卷积神经网络(DCNN)、PATCHY-SAN、Deep Graph CNN(DGCNN)和匿名行走嵌入(AWL)。
- 模型训练:
实验结果:
baseline 模型总结
| 模型 | 说明 | 参考文献 |
|---|---|---|
| WL subtree kernel | 使用C-SVM作为分类器的WL子树内核。调整的超参数包括SVM的C和WL迭代的次数。 | Shervashidze et al., 2011; Chang & Lin, 2011 |
| DCNN | Diffusion-convolutional neural networks | Atwood & Towsley, 2016 |
| PATCHY-SAN | 一种深度学习架构 | Niepert et al., 2016 |
| DGCNN | Deep Graph CNN | Zhang et al., 2018 |
| AWL | Anonymous Walk Embeddings | Ivanov & Burnaev, 2018 |
数据集和任务说明
| 数据集 | 说明 | 任务 | 参考链接 |
|---|---|---|---|
| IMDB-BINARY | 电影合作数据集。每个图对应一个演员的自我网络,节点对应演员,如果他们出现在同一部电影中则有一条边。 | 对其来源的电影类型进行分类 | Yanardag & Vishwanathan, 2015 |
| IMDB-MULTI | 与IMDB-BINARY类似,但涉及多种电影类型。 | 对其来源的电影类型进行分类 | Yanardag & Vishwanathan, 2015 |
| REDDIT-BINARY | 每个图对应一个在线讨论线程,节点对应用户。如果其中一个回应了另一个的评论,则两个节点之间有一条边。 | 对每个图进行分类,属于哪个社区或子reddit | Yanardag & Vishwanathan, 2015 |
| REDDIT-MULTI5K | 与REDDIT-BINARY类似,但涉及多个社区或子reddit。 | 对每个图进行分类,属于哪个社区或子reddit | Yanardag & Vishwanathan, 2015 |
| COLLAB | 科学合作数据集,来源于3个公共合作数据集:高能物理、冷凝物质物理和天体物理。 | 对每个图进行分类,属于哪个研究领域 | Yanardag & Vishwanathan, 2015 |
| MUTAG | 188种致突变的芳香和杂环硝基化合物数据集,有7个离散标签。 | 化学物质分类 | - |
| PROTEINS | 节点是二级结构元素(SSEs),如果它们在氨基酸序列或3D空间中是邻居,则两个节点之间有一条边。有3个离散标签。 | 蛋白质结构分类 | - |
| PTC | 344种化学化合物的数据集,报告了雄性和雌性大鼠的致癌性,有19个离散标签。 | 化学物质分类 | - |
| NCI1 | 由国家癌症研究所(NCI)公开提供的数据集,是化学化合物的一个子集,这些化学化合物被筛选出来用于抑制或抑制人类肿瘤细胞系的生长。 | 化学物质分类 | - |
思考与分析
GNNs 的理论分析:
- 本文提供了对 GNNs 表现力的深入理论分析,揭示了其与 WL 图同构测试之间的紧密联系。主要说明了,一个具有好的表示(优秀的分类能力)的GNN是
单射的, 也就是说,它不会将不相同的图编码成相同的向量,如果两个图是同构的,那么其编码得到的向量一定是相同的。 其通过将一个节点的临近节点考虑成为一个可以带有重复元素的集合来实现。
- 同构的图被编码成相同的Tensor
- 不同构的图被编码成不同的Tensor
- if the neighbor aggregation and graph-level readout functions are injective, then
the resulting GNN is as powerful as the WL test.实践与理论的结合:
项目/模型 一般的GNN GIN 公式 $$ h_v^{(l+1)} = \sigma \left( W^{(l)} \cdot \text{AGGREGATE}^{(l)}\left( { h_u^{(l)} : u \in \mathcal{N}(v) } \right) \right) $$ $$ h_v^{(k)}=\phi\left(h_v^{(k-1)}, f\left(\left{h_u^{(k-1)}: u \in \mathcal{N}(v)\right}\right)\right) $$ 聚合方式 使用AGGREGATE函数聚合邻居的信息 聚合函数 $ f $ 直接对邻居的特征进行求和 考虑节点自身特征 不直接考虑 通过更新函数$ \phi $ 明确地考虑了节点自身的特征 说明 一般的GNN主要依赖于邻居的特征聚合来更新节点的特征 GIN则通过更新函数 $\phi $ 同时考虑了节点自身的特征和其邻居的特征 其中$\phi$函数可以用一般的
MLP表示,或者用1-LAYER来表示:
$$
h_v^{(k)}=\operatorname{MLP}^{(k)}\left(\left(1+\epsilon^{(k)}\right) \cdot h_v^{(k-1)}+\sum_{u \in \mathcal{N}(v)} h_u^{(k-1)}\right)
$$本文总结
本文收到
WL图同构测试算法的启发, 提出一个好的GNN神经网络应该具有以下的特征, 量化了对于一个图神经网络的表示性的好坏在数学上的表示:
- 同构的图被编码成相同的Tensor
- 不同构的图被编码成不同的Tensor
- if the neighbor aggregation and graph-level readout functions are injective, then
the resulting GNN is as powerful as the WL test.本文主要是通过修改对于每个
Vertex的表征手段来实现的, 通过构建\phi函数,考虑临近节点和自身来构建表示。
graphormer 相关论文
| 论文名称 | 作者 | 会议/期刊 | 年份 | 摘要/简介 | 论文链接 | 作者单位 |
|---|---|---|---|---|---|---|
| Do Transformers Really Perform Bad for Graph Representation? | Ying, CX; Cai, TL; (…); Liu, TY | 35th Conference on Neural Information Processing Systems (NeurIPS) | 2021 | The Transformer architecture has become a dominant choice in many domains… | 链接 | (未提及) |
| Mesh Graphormer | Lin, K; Wang, LJ; Liu, ZC | 18th IEEE/CVF International Conference on Computer Vision (ICCV) | 2021 | We present a graph-convolution-reinforced transformer, named Mesh Graphormer… | 链接 | (未提及) |
| Two-Stream Spatial Graphormer Networks for Skeleton-Based Action Recognition | Li, XL; Zhang, JY; (…); Zhou, Q | IEEE Aceess | 2022 | In skeleton-based human action recognition, Transformer… | (未提供) | (未提及) |
| Multi-Modal Motion Prediction with Graphormers | Wonsak, S; Al-Rifai, M; (…); Nejdl, W | IEEE 25th International Conference on Intelligent Transportation Systems (ITSC) | 2022 | Urban road traffic is a highly dynamic environment… | (未提供) | (未提及) |
| STGlow: A Flow-Based Generative Framework With Dual-Graphormer for Pedestrian Trajectory Prediction | Liang, RQ; Li, YM; (…); Li, X | (未提及) | Jul 2023 | The pedestrian trajectory prediction task is an essential component… | (未提供) | (未提及) |
| DrugormerDTI: Drug Graphormer for drug-target interaction prediction | Hu, JY; Yu, W; (…); Wei, LY | (未提及) | Jul 2023 | Drug-target interactions (DTI) prediction is a crucial task… | (未提供) | (未提及) |
| Learning with uncertainty to accelerate the discovery of histone lysine-specific demethylase 1A (KDM1A/LSD1) inhibitors | Wang, D; Wu, ZX; (…); Hou, TJ | (未提及) | 2023 | Machine learning including modern deep learning models… | (未提供) | (未提及) |
| Bidirectional Graphormer for Reactivity Understanding: Neural Network Trained to Reaction Atom-to-Atom Mapping Task | Nugmanov, R; Dyubankova, N; (…); Wegner, JK | (未提及) | Jul 25 2022 | This work introduces GraphormerMapper, a new algorithm… | (未提供) | (未提及) |
| Exploring graph capsual network and graphormer for graph classification | Zuo, XL; Yuan, H; (…); Wang, Y | (未提及) | Sep 2023 | Graph Neural Networks (GNNs) have achieved significant success… | (未提供) | (未提及) |
| Self-supervised learning with chemistry-aware fragmentation for effective molecular property prediction. | Xie, Ailin; Zhang, Ziqiao; (…); Zhou, Shuigeng | (未提及) | 2023-aug-20 | Molecular property prediction (MPP) is a crucial and fundamental task… | (未提供) | (未提及) |
| Spectral Graphormer: Spectral Graph-based Transformer for Egocentric Two-Hand Reconstruction using Multi-View Color Images | (未提及) | ICCV 2023 | 2023 | (未提及) | 链接 | (未提及) |
| Curvature-based Transformer for Molecular Property Prediction | (未提及) | (未提及) | 2023 | (未提及) | 链接 | (未提及) |
| Learning to Group Auxiliary Datasets for Molecule | (未提及) | (未提及) | 2023 | (未提及) | 链接 | (未提及) |
| CardiGraphormer: Unveiling the Power of Self-Supervised Learning in Revolutionizing Drug Discovery | (未提及) | (未提及) | 2023 | (未提及) | 链接 | (未提及) |
| Graph Interpolation via Fast Fused-Gromovization | (未提及) | (未提及) | 2023 | (未提及) | 链接 | (未提及) |
| Towards Predicting Equilibrium Distributions for Molecular Systems with Deep Learning | (未提及) | (未提及) | 2023 | (未提及) | 链接 | (未提及) |
| STGlow: A Flow-based Generative Framework with Dual Graphormer for Pedestrian Trajectory Prediction | (未提及) | (未提及) | 2022 | (未提及) | 链接 | (未提及) |
| An Empirical Study of Graphormer on Large-Scale Molecular Modeling Datasets | (未提及) | (未提及) | 2022 | (未提及) | 链接 | (未提及) |
| Benchmarking Graphormer on Large-Scale Molecular Modeling Datasets | (未提及) | (未提及) | 2022 | (未提及) | 链接 | (未提及) |
| First Place Solution of KDD Cup 2021 & OGB Large-Scale Challenge Graph Prediction Track | (未提及) | (未提及) | 2021 | (未提及) | 链接 | (未提及) |
graphormer细读文献
| 论文名称 | 作者 | 会议/期刊 | 年份 | 摘要/简介 | 论文链接 | 作者单位 |
|---|---|---|---|---|---|---|
| Mesh Graphormer | Lin, K; Wang, LJ; Liu, ZC | 18th IEEE/CVF International Conference on Computer Vision (ICCV) | 2021 | We present a graph-convolution-reinforced transformer, named Mesh Graphormer… | 链接 | (未提及) |
| Two-Stream Spatial Graphormer Networks for Skeleton-Based Action Recognition | Li, XL; Zhang, JY; (…); Zhou, Q | IEEE Access | 2022 | In skeleton-based human action recognition, Transformer… | (未提供) | (未提及) |
| Multi-Modal Motion Prediction with Graphormers | Wonsak, S; Al-Rifai, M; (…); Nejdl, W | IEEE 25th International Conference on Intelligent Transportation Systems (ITSC) | 2022 | Urban road traffic is a highly dynamic environment… | (未提供) | (未提及) |
| Spectral Graphormer: Spectral Graph-based Transformer for Egocentric Two-Hand Reconstruction using Multi-View Color Images | (未提及) | ICCV 2023 | 2023 | (未提及) | 链接 | (未提及) |

作者:Kevin Lin, Lijuan Wang, Zicheng Liu
作者提出了Mesh Graphormer,这是一个图卷积增强的变压器,用于从单张图片中重建3D人体姿势和网格。近期,变压器和图卷积神经网络(GCNNs)在人体网格重建中都显示出了很好的进展。本文研究如何在变压器中结合图卷积和自注意力来模拟局部和全局的交互。
(2021)
- 被引用次数:18th IEEE/CVF International Conference on Computer Vision (ICCV)
- arXiv
- 摘要:本文提出了一个图卷积增强的变压器,名为 Mesh Graphormer,用于从单张图片中重建3D人体姿势和网格。近期,变压器和图卷积神经网络(GCNNs)在人体网格重建中都显示出了很好的进展。本文研究如何在变压器中结合图卷积和自注意力来模拟局部和全局的交互。实验结果显示,Mesh Graphormer 在多个基准测试中都明显优于之前的最先进方法,包括 Human3.6M、3DPW 和 FreiHAND 数据集。
- PDF链接
- GitHub仓库链接
前置说明:
- Mesh Graphormer:
- 背景:从单张图片中重建3D人体姿势和网格是一个热门的研究话题,但由于复杂的身体关节,这是一个具有挑战性的任务。
- 主要贡献:本文的目标是结合自注意力和图卷积来重建3D人体网格。
- 方法:介绍了Graphormer编码器的架构,它由N = 4个相同的块组成。每个块包含五个子模块,包括层规范化、多头自注意力模块、图残差块、第二层规范化和最后的多层感知机(MLP)。
- 实验:使用公开可用的数据集进行了广泛的训练,包括Human3.6M、MuCo-3DHP、UP-3D、COCO和MPII。与先前的方法进行了比较,结果显示我们的方法在Human3.6M和3DPW数据集上都优于先前的最先进方法。
论文阅读
- 背景与动机:
- 从单张图片中重建3D人体姿势和网格是一个热门的研究话题。由于复杂的身体关节,这是一个具有挑战性的任务。近期,变压器和图卷积神经网络(GCNNs)在人体网格重建中都显示出了很好的进展。
- Mesh Graphormer 的提出:
- 为了解决上述问题,作者提出了Mesh Graphormer。这是一个图卷积增强的变压器,用于从单张图片中重建3D人体姿势和网格。本文研究如何在变压器中结合图卷积和自注意力来模拟局部和全局的交互。
- Graphormer 编码器:
- 作者详细介绍了Graphormer编码器的架构,它由N = 4个相同的块组成。每个块包含五个子模块,包括层规范化、多头自注意力模块、图残差块、第二层规范化和最后的多层感知机(MLP)。
- 实验结果与分析:
- 作者使用公开可用的数据集进行了广泛的训练,包括Human3.6M、MuCo-3DHP、UP-3D、COCO和MPII。与先前的方法进行了比较,结果显示Mesh Graphormer在Human3.6M和3DPW数据集上都优于先前的最先进方法。
思考与分析
- Transformer 的适应性:
- “Mesh Graphormer” 论文进一步证明了 Transformer 架构在非传统领域的适应性。尽管 Transformer 最初是为 NLP 设计的,但通过适当的修改和增强,它已经被成功地应用于3D人体姿势和网格的重建。
- 图卷积的深入分析:
- 传统的 Transformer 可能在处理图数据时遇到困难,因为图数据的结构和关系比序列数据更为复杂。通过结合图卷积,Mesh Graphormer 能够有效地模拟局部和全局的交互,从而更好地处理图数据。
- 实践与理论的结合:
- 除了实验验证 Mesh Graphormer 的有效性外,论文还详细描述了其编码器的架构和工作原理。这种对模型的深入理解和分析为未来的研究提供了坚实的基础。
- 未来方向:
- 虽然 Mesh Graphormer 在3D人体姿势和网格重建上表现出色,但仍有可能进一步优化或扩展其功能。例如,可以考虑引入更多的图特性或其他类型的编码来进一步提高模型的性能。
总的来说,这篇论文为如何使用图卷积增强的 Transformer 架构处理3D人体姿势和网格的重建提供了有价值的见解。这为未来的研究提供了一个很好的起点,并证明了 Transformer 架构在多种任务和数据类型上的潜力。
Multi-Modal Motion Prediction with Graphormers
作者:Shimon Wonsak, Mohammad Al-Rifai, Michael Nolting, Wolfgang Nejdl
本文探讨了城市道路交通的动态性,由于其复杂的道路布局、交通规则和道路用户互动,准确预测未来位置仍然是一个具有挑战性的任务。尽管最近的运动预测模型受到自然语言处理领域的启发并利用了Transformer架构,但它们完全忽略了数据中固有的图语义。Graphormer是一个新近提出的架构,用于解决分子科学领域的这一挑战。在本文中,作者展示了如何利用Graphormer架构来处理运动预测任务,并提出了一种新的编码策略来创建一个具有局部感知的Graphormer。此外,还扩展了该架构,使其能够通过自注意力机制处理边特征。为了展示所有组件的有效性,作者在公开的Argoverse城市运动预测数据集上评估了模型。定量和定性评估显示,该模型能够进行精确的最先进的预测。
(2022)
被引用次数:未知
IEEE
摘要:城市道路交通是一个高度动态的环境,因为它有许多规则、复杂的道路布局和道路用户互动。因此,准确预测未来位置仍然是一个具有挑战性的任务。受到自然语言处理领域成就的启发,最近的运动预测模型利用了Transformer架构。尽管这些模型产生了最先进的结果,但它们完全忽略了数据中固有的图语义。Graphormer是一个新近提出的架构,用于解决分子科学领域的这一挑战。在本文中,我们展示了如何利用Graphormer架构来处理运动预测任务。我们提出了一种新的编码策略来创建一个具有局部感知的Graphormer。此外,我们还扩展了该架构,使其能够通过自注意力机制处理边特征。为了展示所有组件的有效性,我们在公开的Argoverse城市运动预测数据集上评估了我们的模型。定量和定性评估显示,我们的模型能够进行精确的最先进的预测。
前置说明:
Multi-Modal Motion Prediction with Graphormers:
- 背景:城市道路交通的动态性使得准确预测未来位置成为一个挑战。尽管Transformer架构在运动预测中取得了一定的进展,但现有的模型忽略了数据中的图语义。
- 主要贡献:本文展示了如何利用Graphormer架构来处理运动预测任务,并提出了一种新的编码策略。
- 方法:作者提出了一个具有局部感知的Graphormer,并扩展了该架构,使其能够通过自注意力机制处理边特征。
- 实验:使用公开的Argoverse城市运动预测数据集进行了评估,结果显示该模型能够进行精确的最先进的预测。
论文阅读
- 背景与动机:
- 城市道路交通是一个高度动态的环境,因为其有许多规则、复杂的道路布局和道路用户之间的互动。因此,准确预测未来的位置仍然是一个具有挑战性的任务。受到自然语言处理领域的成果的启发,最近的运动预测模型利用了 Transformer 架构。尽管这些模型产生了最先进的结果,但它们完全忽略了数据中固有的图语义。Graphormer 是一个新近提出的有前景的架构,用于解决分子科学领域的这一挑战。在本文中,我们展示了如何利用 Graphormer 架构来解决运动预测任务。
- Graphormer 的应用:
- 为了解决上述问题,作者展示了如何利用 Graphormer 架构来解决运动预测任务。他们提出了一种新的编码策略来创建一个具有局部性的 Graphormer。此外,他们扩展了该架构,使其能够使用自注意机制处理边特征。为了展示所有组件的有效性,他们在 Argoverse 的公开可用的城市运动预测数据集上评估了他们的模型。定量和定性的评估显示,我们的模型能够进行精确的最先进的预测。
- 结构与编码:
- 作者提出了一种新的图表示,其中每个节点对应于一个中心线点,如果没有明确定义的话,邻接矩阵表示节点之间的连接性。此外,他们为运动预测任务创建了一个图感知的 Transformer,该 Transformer 基于 Graphormer 模型,并引入了新的编码策略,使模型能够捕获运动预测任务的社交和地图图结构。
- 实验结果与分析:
- 作者在公开的 Argoverse 数据集上评估了所提出解决方案的性能。
思考与分析
- Transformer 的适应性:
- 这篇论文进一步证明了 Transformer 架构在处理高度动态的环境,如城市道路交通中的适应性。通过适当的修改和编码,它可以成功地应用于运动预测任务。
- 结构编码的深入分析:
- 传统的 Transformer 模型可能无法捕获图数据的复杂性。这是因为图数据的结构信息与序列数据或图像数据不同。通过引入结构编码,Graphormer 能够更好地理解和表示图结构数据。
- 实践与理论的结合:
- 除了实验验证 Graphormer 的有效性外,作者还展示了如何结合社交和地图信息的图表示来捕获运动预测任务的图结构。
- 未来方向:
- 虽然 Graphormer 在运动预测任务上表现出色,但仍有可能进一步优化或扩展其功能。例如,可以考虑将更多的图特性或其他类型的编码引入模型中。
作者:Tze Ho Elden Tse, Franziska Mueller, Zhengyang Shen, Danhang Tang, Thabo Beeler, Mingsong Dou, Yinda Zhang, Sasa Petrovic, Hyung Jin Chang, Jonathan Taylor, Bardia Doosti
发布日期:(2023)
来源: ICCV 2023
摘要:本文提出了一个新颖的基于变压器的框架,该框架从多视图RGB图像中重建两个高保真的手。与现有的手部姿势估计方法不同,其中通常训练一个深度网络从单个RGB图像回归手模型参数,我们考虑一个更具挑战性的问题设置,其中我们直接从以自我为中心的视图中回归两只手的绝对根姿势,这些手具有高分辨率和扩展的前臂。由于现有的数据集要么不适用于以自我为中心的视点,要么缺乏背景变化,因此我们创建了一个大型合成数据集,并收集了一个真实数据集来验证我们提出的多视图图像特征融合策略。为了使重建物理上合理,我们提出了两种策略:(i)一个粗到细的谱图卷积解码器,在上采样过程中平滑网格;(ii)在推理阶段,一个基于优化的细化阶段,以防止自渗透。通过广泛的定量和定性评估,我们展示了我们的框架能够产生逼真的双手重建,并展示了合成训练模型对真实数据的泛化能力,以及实时的AR/VR应用。
前置说明:
Spectral Graphormer:
背景:3D手部姿势估计在增强和虚拟现实(AR/VR)等多种下游应用中都是一个基本问题。尽管单手姿势估计已经取得了很大的进展,但双手姿势估计相对受到了较少的关注。
主要贡献:本文提出了一个能够从多视图RGB图像中重建高保真双手的谱图基变压器架构。
方法:该方法结合了软注意力机制和变压器编码,以及谱图卷积解码器,以从多视图图像中重建两只手。此外,为了处理物理上不可能的网格,还引入了一个基于优化的细化步骤。
实验:作者创建了一个大型合成多视图数据集,并收集了一个真实数据集来验证所提方法。实验结果显示,该方法在各种挑战性场景中都表现出了强大的性能,并可以作为一个强大的基线。
论文阅读
背景与动机:
- 该论文提出了一个基于Transformer的新颖框架,用于从多视角RGB图像重建两只高保真的手。与现有的手部姿势估计方法不同,该方法考虑了一个更具挑战性的问题设置,即直接从自我中心视图中回归两只手的绝对根姿势。为了使重建物理上合理,作者提出了两种策略:一种是粗到细的光谱图卷积解码器,用于在上采样过程中平滑网格;另一种是在推理阶段的优化基础上的细化阶段,以防止自穿透。
方法:
- 该框架首先将N个多视角RGB输入图像传递给共享的CNN背景,以提取体积特征。然后,这些特征被送入一个基于软注意力的多视角特征编码器,并输出K个区域特定的特征。Transformer编码器接受这些特征以及模板手部网格,并输出一个粗糙的网格表示。最后,光谱图解码器通过在这个粗糙的表示上进行上采样来生成手部网格。
实验结果与分析:
- 作者提出了一个新颖的端到端可训练的光谱图基于Transformer的方法,用于从多视角RGB图像中重建高保真的两只手。他们设计了一种有效的基于软注意力的多视角图像特征融合方法,通过这种方法,得到的图像特征是区域特定的,与分段手部网格相关。此外,他们还引入了一种优化方法,用于在推理时细化物理上不合理的网格。为了验证所提出的方法,他们创建了一个大规模的合成多视角数据集,并收集了真实数据集。
思考与分析
Transformer 的适应性:
- 该论文进一步证明了Transformer架构在处理如两只手的重建这样的复杂任务中的适应性。通过适当的设计和编码,它可以成功地应用于这种任务。
多视角融合的重要性:
- 通过软注意力机制和Transformer编码器,该方法能够有效地融合来自多个视角的图像特征,从而提供更准确和详细的手部重建。
实践与理论的结合:
- 除了实验验证其方法的有效性外,作者还展示了如何结合光谱图理论和Transformer架构来处理这个问题。这种结合为未来的研究提供了一个有价值的方向。
未来方向:
- 虽然该方法在手部重建任务上表现出色,但仍有可能进一步优化或扩展其功能。例如,可以考虑引入更多的图特性或其他类型的编码来进一步提高重建的准确性。
总的来说,这篇论文为如何使用Transformer架构处理两只手的重建任务提供了有价值的见解,并提出了一个有效的解决方案。这为未来的研究提供了一个很好的起点,并证明了Transformer架构在多种任务和数据类型上的潜力。
graphormer相关文献阅读总结
| 论文名称 | 主要贡献 | 方法描述 | 实验结果与分析 | 思考与分析 |
|---|---|---|---|---|
| Mesh Graphormer | 提出了Mesh Graphormer,一个图卷积增强的变压器,用于从单张图片中重建3D人体姿势和网格。 | 结合自注意力和图卷积来重建3D人体网格。 | 在Human3.6M、3DPW等数据集上优于先前的最先进方法。 | 证明了Transformer架构在非传统领域的适应性,以及图卷积在处理图数据时的重要性。 |
| Multi-Modal Motion Prediction with Graphormers | 展示了如何利用Graphormer架构来处理运动预测任务,并提出了一种新的编码策略。 | 利用Graphormer架构处理运动预测任务,并引入了新的编码策略来创建一个具有局部感知的Graphormer。 | 在Argoverse城市运动预测数据集上表现出色。 | 证明了Transformer架构在处理高度动态的环境中的适应性,以及结构编码在处理图数据时的重要性。 |
| Spectral Graphormer: Spectral Graph-based Transformer for Egocentric Two-Hand Reconstruction using Multi-View Color Images | 提出了一个基于Transformer的新颖框架,用于从多视角RGB图像重建两只高保真的手。 | 结合了软注意力机制和变压器编码,以及谱图卷积解码器,以从多视图图像中重建两只手。 | 创建了一个大型合成多视图数据集,并收集了一个真实数据集来验证所提方法。 | 证明了Transformer架构在处理如两只手的重建这样的复杂任务中的适应性,以及多视角融合的重要性。 |
Graphormer 代码阅读与使用
Graphormer结构:
encoder示意图:
graph TD A[Input: batched_data] --> B[GraphNodeFeature] A --> C[GraphAttnBias] B --> D[Token Embeddings] D --> E[Optional: Perturb] E --> F[Embed Scale] F --> G[Quant Noise] G --> H[Emb Layer Norm] H --> I[Dropout] I --> J[Transpose] J --> K[GraphormerGraphEncoderLayer] K --> L[Graph Representation] L --> M[Output: inner_states, graph_rep] style A fill:#f9d,stroke:#333,stroke-width:2px style M fill:#f9d,stroke:#333,stroke-width:2px在前向传播过程中的结构:
graph TD A[Input: batched_data] --> B[Compute Padding Mask] B --> C[Token Embeddings] C --> D[Optional: Perturb] D --> E[GraphAttnBias] E --> F[Embed Scale] F --> G[Quant Noise] G --> H[Emb Layer Norm] H --> I[Dropout] I --> J[Transpose] J --> K1[GraphormerGraphEncoderLayer 1] K1 --> K2[GraphormerGraphEncoderLayer 2] ... Kn[GraphormerGraphEncoderLayer n] --> L[Graph Representation] L --> M[Output: inner_states, graph_rep] style A fill:#f9d,stroke:#333,stroke-width:2px style M fill:#f9d,stroke:#333,stroke-width:2pxgraph TD A[Input: batched_data] --> B[Extract x, in_degree, out_degree] B --> C1[Atom Encoder] B --> C2[In Degree Encoder] B --> C3[Out Degree Encoder] C1 --> D[Node Feature] C2 --> D C3 --> D E[Graph Token] --> D D --> F[Concatenate Graph Token Feature] F --> G[Output: graph_node_feature] style A fill:#f9d,stroke:#333,stroke-width:2px style G fill:#f9d,stroke:#333,stroke-width:2px
- GraphAttnBias
graph TD A[Input: batched_data] --> B[Extract attn_bias, spatial_pos, x, edge_input, attn_edge_type] B --> C1[Spatial Pos Encoder] B --> C2[Graph Token Virtual Distance] C1 --> D[Spatial Pos Bias] C2 --> D B --> E1[Edge Encoder] E1 --> F[Edge Input] B --> E2[Edge Dis Encoder] E2 --> F F --> G[Edge Input Processing] G --> H[Combine Spatial Pos Bias and Edge Input] H --> I[Output: graph_attn_bias] style A fill:#f9d,stroke:#333,stroke-width:2px style I fill:#f9d,stroke:#333,stroke-width:2px安装
conda create -n graphormer python=3.9 conda activate graphormer、 git clone --recursive https://github.com/microsoft/Graphormer.git cd Graphormer bash install.sh
- 示例使用
cd examples/property_prediction/ bash zinc.sh其中
zinc.sh内容为:CUDA_VISIBLE_DEVICES=0 fairseq-train \ --user-dir ../../graphormer \ --num-workers 16 \ --ddp-backend=legacy_ddp \ --dataset-name zinc \ --dataset-source pyg \ --task graph_prediction \ --criterion l1_loss \ --arch graphormer_slim \ --num-classes 1 \ --attention-dropout 0.1 --act-dropout 0.1 --dropout 0.0 \ --optimizer adam --adam-betas '(0.9, 0.999)' --adam-eps 1e-8 --clip-norm 5.0 --weight-decay 0.01 \ --lr-scheduler polynomial_decay --power 1 --warmup-updates 60000 --total-num-update 400000 \ --lr 2e-4 --end-learning-rate 1e-9 \ --batch-size 64 \ --fp16 \ --data-buffer-size 20 \ --encoder-layers 12 \ --encoder-embed-dim 80 \ --encoder-ffn-embed-dim 80 \ --encoder-attention-heads 8 \ --max-epoch 10000 \ --save-dir ./ckpts
- 验证效果
python evaluate.py \ --user-dir ../../graphormer \ --num-workers 16 \ --ddp-backend=legacy_ddp \ --dataset-name pcqm4m \ --dataset-source ogb \ --task graph_prediction \ --criterion l1_loss \ --arch graphormer_base \ --num-classes 1 \ --batch-size 64 \ --pretrained-model-name pcqm4mv1_graphormer_base \ --load-pretrained-model-output-layer \ --split valid \ --seed 1
Baseline 模型总结
| 模型 | 说明 | 参考文献 |
|---|---|---|
| GCN | 经典的图神经网络模型 | [26] |
| GIN | 流行的图神经网络模型 | [54] |
| GCN-VN | GCN的虚拟节点版本 | [15] |
| GIN-VN | GIN的虚拟节点版本 | [15] |
| GIN的多跳变体 | 考虑了多跳的信息的GIN变种 | [5] |
| DeeperGCN | 12层深的图神经网络模型 | [30] |
| GT | 基于Transformer的图模型 | [13] |
| Graphormer | 作者提出的模型,大小为(L = 12, d = 768) | - |
| GraphormerS MALL | 作者提出的较小版本模型,大小为(L = 6, d = 512) | - |
| WL subtree kernel | 使用C-SVM作为分类器的WL子树内核。调整的超参数包括SVM的C和WL迭代的次数。 | Shervashidze et al., 2011; Chang & Lin, 2011 |
| DCNN | Diffusion-convolutional neural networks | Atwood & Towsley, 2016 |
| PATCHY-SAN | 一种深度学习架构 | Niepert et al., 2016 |
| DGCNN | Deep Graph CNN | Zhang et al., 2018 |
| AWL | Anonymous Walk Embeddings | Ivanov & Burnaev, 2018 |
数据集和任务说明
| 数据集 | 说明 | 任务 | 参考链接 |
|---|---|---|---|
| PCQM4M-LSC | 来自OGB Large-Scale Challenge的量子化学回归数据集,包含超过3.8M的图。 | 回归 | OGB-LSC |
| OGBG-MolPCBA | OGB的一个数据集,用于分子预测。 | 二元分类 | OGB |
| OGBG-MolHIV | OGB的一个数据集,用于HIV活性预测。 | 二元分类 | OGB |
| ZINC (sub-set) | 一个用于分子属性预测的数据集的子集。 | 回归 | - |
| IMDB-BINARY | 电影合作数据集。每个图对应一个演员的自我网络,节点对应演员,如果他们出现在同一部电影中则有一条边。 | 对其来源的电影类型进行分类 | Yanardag & Vishwanathan, 2015 |
| IMDB-MULTI | 与IMDB-BINARY类似,但涉及多种电影类型。 | 对其来源的电影类型进行分类 | Yanardag & Vishwanathan, 2015 |
| REDDIT-BINARY | 每个图对应一个在线讨论线程,节点对应用户。如果其中一个回应了另一个的评论,则两个节点之间有一条边。 | 对每个图进行分类,属于哪个社区或子reddit | Yanardag & Vishwanathan, 2015 |
| REDDIT-MULTI5K | 与REDDIT-BINARY类似,但涉及多个社区或子reddit。 | 对每个图进行分类,属于哪个社区或子reddit | Yanardag & Vishwanathan, 2015 |
| COLLAB | 科学合作数据集,来源于3个公共合作数据集:高能物理、冷凝物质物理和天体物理。 | 对每个图进行分类,属于哪个研究领域 | Yanardag & Vishwanathan, 2015 |
| MUTAG | 188种致突变的芳香和杂环硝基化合物数据集,有7个离散标签。 | 化学物质分类 | - |
| PROTEINS | 节点是二级结构元素(SSEs),如果它们在氨基酸序列或3D空间中是邻居,则两个节点之间有一条边。有3个离散标签。 | 蛋白质结构分类 | - |
| PTC | 344种化学化合物的数据集,报告了雄性和雌性大鼠的致癌性,有19个离散标签。 | 化学物质分类 | - |
| NCI1 | 由国家癌症研究所(NCI)公开提供的数据集,是化学化合物的一个子集,这些化学化合物被筛选出来用于抑制或抑制人类肿瘤细胞系的生长。 | 化学物质分类 | - |