
这个博客主要记录在学习Python的使用技巧, 关于
异步编程,decorator,GIL,CPython的学习和使用。
Python CookBook
下面内容取自
python cookbook, 这本书其实很久前我就读过,不过由于没有使用过,导致基本现在没有什么印象了,现在重温下。
数据结构与算法
文件和IO
读取文本出现错误的编码, 如果无法进行正确的编码, 可以通过
errors参数来处理:with open("sample.txt", "r", encoding="utf-8", errors="replace"): pass除了
replace还可以选择ignore,
假设我们有一个名为sample.txt的文件,其内容为:
Hello, world!
你好,世界!
Hello, ���!
其中,���代表一些无法识别或无法正确解码的字符。
- 使用
replace处理错误:
with open("sample.txt", "r", encoding="utf-8", errors="replace") as file:
content = file.read()
print(content)
输出:
Hello, world!
你好,世界!
Hello, �!
可以看到,无法解码的字符���被替换为了一个�字符。
- 使用
ignore处理错误:
with open("sample.txt", "r", encoding="utf-8", errors="ignore") as file:
content = file.read()
print(content)
输出:
Hello, world!
你好,世界!
Hello, !
可以看到,无法解码的字符���被完全忽略了,所以在输出中它们完全消失了。
这个例子展示了如何使用replace和ignore参数来处理读取文件时遇到的编码错误。
- 将输出重定向到文件
只需要这样做就行了:
with open("somefile.txt", "r") as f:
print("xxxx", file=f)
在Python中,当你打开一个文件,你可以指定文件的模式。对于文本文件,最常用的模式是'r'(读取)和'w'(写入)。但除此之外,还可以指定文件是以文本模式还是二进制模式打开的。这是通过在模式字符串中添加't'或'b'来实现的。
'r' vs 'rt':
'r': 这是默认的文件打开模式,它表示以文本模式打开文件进行读取。在大多数情况下,当你只写'r'时,它实际上是'rt',因为默认情况下文件是以文本模式打开的。'rt': 这明确地表示以文本模式打开文件进行读取。在文本模式下,Python会自动处理平台特定的行结束符。例如,在Windows上,行结束符是\r\n,而在Unix和Linux上是\n。当你在文本模式下读取或写入文件时,Python会自动将这些转换为适当的行结束符。
- 读写二进制文件
在读写文件的时候, 通过rb和wb便可以进行二进制数据的读写, 写入的时候需要使用比如说:
b"This is a byte string"
在Python中,字符串(string)和字节串(byte string)是两种不同的数据类型,尽管它们在许多情境中都用于表示文本。以下是它们之间的主要区别以及一些示例:
定义:
- 字符串 (string): 在Python中,字符串是由Unicode字符组成的序列。在Python 3中,字符串是默认的文本表示形式。
- 字节串 (byte string): 字节串是字节的序列,而不是Unicode字符。它们通常用于表示非文本数据或在需要原始字节数据的情境中。
字面量表示:
- 字符串: 使用单引号或双引号来定义。
s = "This is a string" - 字节串: 使用前缀
b,后跟单引号或双引号。b = b"This is a byte string"
- 字符串: 使用单引号或双引号来定义。
用途:
- 字符串: 用于文本处理,如格式化、搜索、替换等。
- 字节串: 用于二进制数据处理,如文件I/O(特别是二进制文件),网络通信,以及与需要字节数据的库或API的交互。
示例:
编码和解码:
字符串可以被编码为字节串,通常使用某种字符编码(如UTF-8)。反之,字节串可以被解码为字符串。s = "你好" encoded = s.encode('utf-8') # 编码为UTF-8格式的字节串 print(encoded) # 输出: b'\xe4\xbd\xa0\xe5\xa5\xbd' decoded = encoded.decode('utf-8') # 解码为字符串 print(decoded) # 输出: 你好文件操作:
当读取或写入二进制文件(如图像、音频或非文本格式的文件)时,通常使用字节串。with open('image.jpg', 'rb') as f: # 'rb' 表示二进制读取模式 data = f.read() # data 是一个字节串
注意事项:
- 在Python 3中,字符串和字节串不能直接进行许多操作(如连接或比较),除非它们都是相同的类型。尝试这样做会导致TypeError。
- 字符串和字节串在内部表示和存储方式上有所不同。字符串使用Unicode,可以直接表示世界上的大多数字符。而字节串只是原始字节,需要某种字符编码来解释这些字节为文本。
文件读写的
X模式和W模式
在Python的文件操作中,'x' 和 'w' 是两种不同的文件打开模式,它们都与文件写入有关,但它们的行为有所不同。
‘w’ 模式 (写模式):
- 如果文件不存在,它会创建一个新文件。
- 如果文件已经存在,它会覆盖(即清空)该文件的内容。
- 主要用于写入文件,但如果文件已经存在,原有的内容会被新内容替代。
‘x’ 模式 (独占创建模式):
- 该模式只用于文件的创建。
- 如果文件不存在,它会创建一个新文件。
- 如果文件已经存在,它会引发一个
FileExistsError异常。 - 主要用于确保文件是新创建的,而不是覆盖现有文件。
示例:
考虑一个名为example.txt的文件,该文件已经存在并包含一些文本。
使用
'w'模式:with open('example.txt', 'w') as f: f.write('New content')这会清空
example.txt的内容,并只写入New content。使用
'x'模式:with open('example.txt', 'x') as f: f.write('New content')由于
example.txt已经存在,这会引发一个FileExistsError异常。
总结:
- 如果您想写入一个文件,但不希望意外地覆盖现有文件,使用
'x'模式是一个好选择。 - 如果您想写入一个文件,并且不介意覆盖现有文件(如果它存在的话),使用
'w'模式。
这两种模式都可以与其他模式组合,例如'xb'(独占创建二进制模式)或'wb'(写二进制模式)。
- 创建零时文件:
- TemporaryFile()
- NamedTemporaryFile()
- TemporaryDictory()
包和模块管理
尽管我们很多人曾经或多或少学习或者了过, 但是对于部分具体的实现和使用可能不清楚。比如我们在做项目的时候,很多时候跨级导入会出现找不到包的很多错误, 这一章将详细的介绍具体的原理实现,以求尽量在导入和包管理的部分不会出现问题。
最简单无脑,不会出错的导包机制
比如说你的项目名叫graphics的项目,你的目录结构如下:
graphics/
│
├── graphics/
│ ├── __init__.py
│ ├── models/
│ │ ├── __init__.py
│ │ ├── circle.py
│ │ ├── rectangle.py
│ │ └── triangle.py
│ │
│ ├── utils/
│ │ ├── __init__.py
│ │ ├── color_utils.py
│ │ └── math_utils.py
│ │
│ └── main.py
│
├── tests/
│ ├── __init__.py
│ ├── test_circle.py
│ ├── test_rectangle.py
│ └── test_triangle.py
│
├── docs/
│ ├── index.md
│ └── ...
│
├── setup.py
├── README.md
└── .gitignore
在导入的时候,只需要类似:
在提供的graphics项目结构中,导入包和模块的方式取决于你当前的文件位置以及你想要导入的模块。以下是一些基于该项目结构的导入示例:
- 从项目的主模块或脚本中导入:
假设你在main.py中并想导入一些模块:
# main.py
# 导入models子包中的模块
from graphics.models import circle
from graphics.models import rectangle
# 导入utils子包中的模块
from graphics.utils import color_utils
- 从子包中导入其他子包或模块:
假设你在circle.py中并想导入math_utils模块:
# circle.py
# 导入同一主包下的其他子包模块
from graphics.utils import math_utils
- 从测试目录导入主包中的模块:
假设你在test_circle.py中并想测试circle模块:
# test_circle.py
# 导入主包中的模块
from graphics.models import circle
- 导入同一模块中的类或函数:
如果color_utils.py中有一个函数叫做convert_to_grayscale,并且你想在同一模块中的另一个函数里使用它,你可以直接调用它,不需要任何导入。
- 导入模块中的特定类或函数:
假设circle.py中有一个类叫做Circle,你可以这样导入它:
from graphics.models.circle import Circle
使用相对路径导入
当然,除了上面的使用绝对路径的导入外,还能使用相对路径来导入:
from . import X
from ..X import X
采用相对路径导入的优势是不需要进行硬编码导入,方便修改。
importlib
使用importlib可以实现非常复杂的导入,包括hook钩子注入导入等操作,具体我不理解,相关联可以观看官方文档。
利用pyvenv创建并使用环境
创建虚拟环境:
使用以下命令创建虚拟环境。这里,我们将虚拟环境命名为
myenv:python3 -m venv myenv如果你有多个 Python 版本并想为虚拟环境指定一个特定版本,你可以使用相应的 Python 版本号,例如:
python3.8 -m venv myenv激活虚拟环境:
Linux/macOS:
source myenv/bin/activateWindows:
myenv\Scripts\activate
激活后,你的命令提示符或终端将显示虚拟环境的名称,表明你当前正在该环境中。
在虚拟环境中安装包:
使用
pip在虚拟环境中安装 Python 包:pip install some_package这些包只会安装在虚拟环境中,不会影响全局的 Python 安装。
停用虚拟环境:
当你想退出虚拟环境时,使用以下命令:
deactivate这将停用虚拟环境并返回到全局 Python 环境。
删除虚拟环境:
要删除虚拟环境,只需删除其目录:
Linux/macOS:
rm -rf myenvWindows:
rmdir /s /q myenv
这就是使用 venv 创建、使用和删除 Python 虚拟环境的全流程。使用虚拟环境是管理 Python 项目和其依赖关系的推荐方法,因为它可以确保项目的依赖关系与全局安装的包保持隔离。
创建并发布自己的包
创建了 .egg-info 文件后,你已经为你的包生成了一些元数据。接下来,如果你想将你的包上传到 PyPI (Python Package Index),你可以按照以下步骤操作:
创建PyPI账户:
如果你还没有PyPI账户,首先需要在 PyPI官网 上注册一个。安装 twine:
twine是一个用于上传包到 PyPI 的工具。你可以使用pip来安装它:pip install twine生成分发包:
使用setup.py生成一个源分发包和一个轮子分发包:python setup.py sdist bdist_wheel这会在
dist/目录下生成.tar.gz和.whl文件。上传包到 PyPI:
使用twine将你的包上传到 PyPI:twine upload dist/*这时,
twine会提示你输入在 PyPI 上的用户名和密码。完成:
上传完成后,你的包应该可以在 PyPI 上找到,并且可以使用pip进行安装。
注意事项:
- 在上传之前,确保你的
setup.py文件中的信息是完整和准确的,特别是版本号。每次上传到 PyPI 的版本都必须是唯一的,所以如果你对包进行了更新,确保也更新了版本号。 - 如果你只是进行了测试或者不想立即将你的包公开,你可以先上传到 TestPyPI 进行测试。这需要在使用
twine上传时指定仓库的URL:twine upload --repository-url https://test.pypi.org/legacy/ dist/*。
比如说我的项目结构为:
编写好setup.py 如下:
# setup.py
from distutils.core import setup
setup(
name='xxxx',
version='0.1.0',
author='xxxx',
author_email='xxxx',
url='https://blog.dingli.life',
packages=['xxxx'],
)
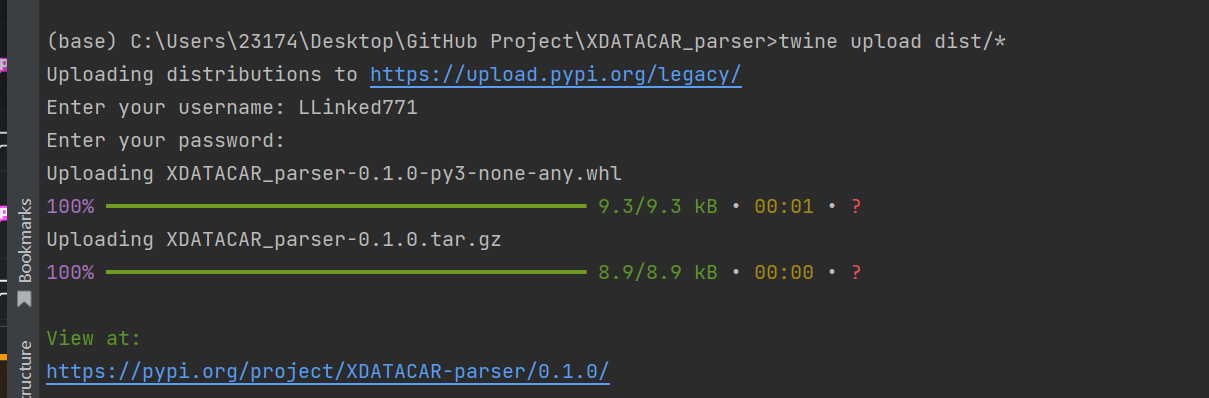
然后按照上面说明的运行命令,并上传,你就能看到的你的包已经被上传到Python了:
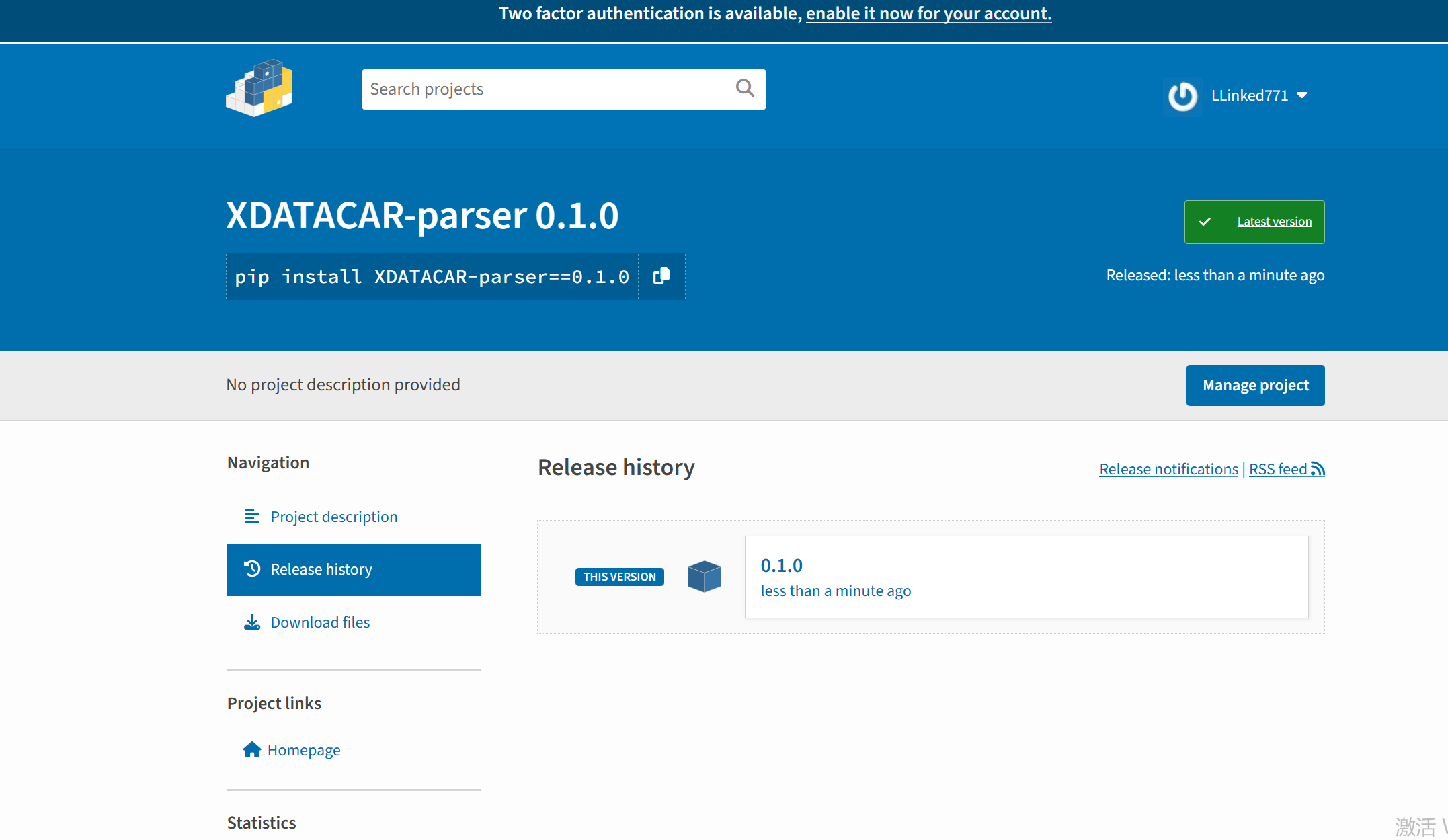
然后访问链接,就能看到自己的Python包的主页了!:
并发和多线程控制
系统管理
测试,调试,异常
C语言扩展
ww