
项目介绍
深度学习系统,主要是实现一个类似pytorch的深度学习框架,包括计算图传播和GPU加速.
- github链接:linkedlist771/DeepLearningSystem: 深度学习系统,主要是实现一个类似pytorch的深度学习框架,包括计算图传播和GPU加速 (github.com)
踩过的坑
Linear层神经网络前向传播, 代码如下:
class Linear(Module):
def __init__(self, in_features, out_features, bias=True, device=None, dtype="float32"):
super().__init__()
self.in_features = in_features
self.out_features = out_features
### BEGIN YOUR SOLUTION
#self.bias = bias
self.device = device
self.dtype = dtype
# 如果有偏置的话
weight = init.kaiming_uniform(in_features, out_features, nonlinearity="relu", device=device, dtype=dtype)
self.weight = Tensor(weight)
if bias:
# 然而,如果你的代码中某些地方假定偏置是一个二维张量,而且第一个维度为1,那么reshape就是必须的。
# 这可能是为了保持与特定操作的兼容性,例如广播或矩阵乘法。
# 另外一种可能的原因是,在使用Kaiming初始化时,fan_in和fan_out参数的顺序可能会影响到初始化的结果。
# 在你的代码中,可能作者想要使用out_features作为fan_in来进行初始化。然后,通过reshape操作将偏置调整为正确的形状。
# 不过在偏置初始化中,一般不需要这样做,因为偏置通常都被初始化为零或者接近零的小值。
self.bias = init.kaiming_uniform(out_features, 1, dtype=dtype).reshape((1, out_features))
# self.bias = init.kaiming_uniform(1, out_features, nonlinearity="relu", device=device, dtype=dtype)
else:
self.bias = None
# raise NotImplementedError()
### END YOUR SOLUTION
def forward(self, X: Tensor) -> Tensor:
### BEGIN YOUR SOLUTION
if self.bias:
# 如果有偏置的话
a_l = ops.matmul(X, self.weight)
return a_l + self.bias
else:
return ops.matmul(X, self.weight)
# raise NotImplementedError()
## END YOUR SOLUTION
踩坑点:如果含有偏置bias的情况下,由于out_features可能不是一维的,默认生成(1,out_features) 形状的张量, 在多维情况将出现错误,所以需要init.kaiming_uniform(out_features, 1, dtype=dtype).reshape((1, out_features))先生成这种形状的Tensor然后进行reshape保持兼容性。
一个两层的神经网络
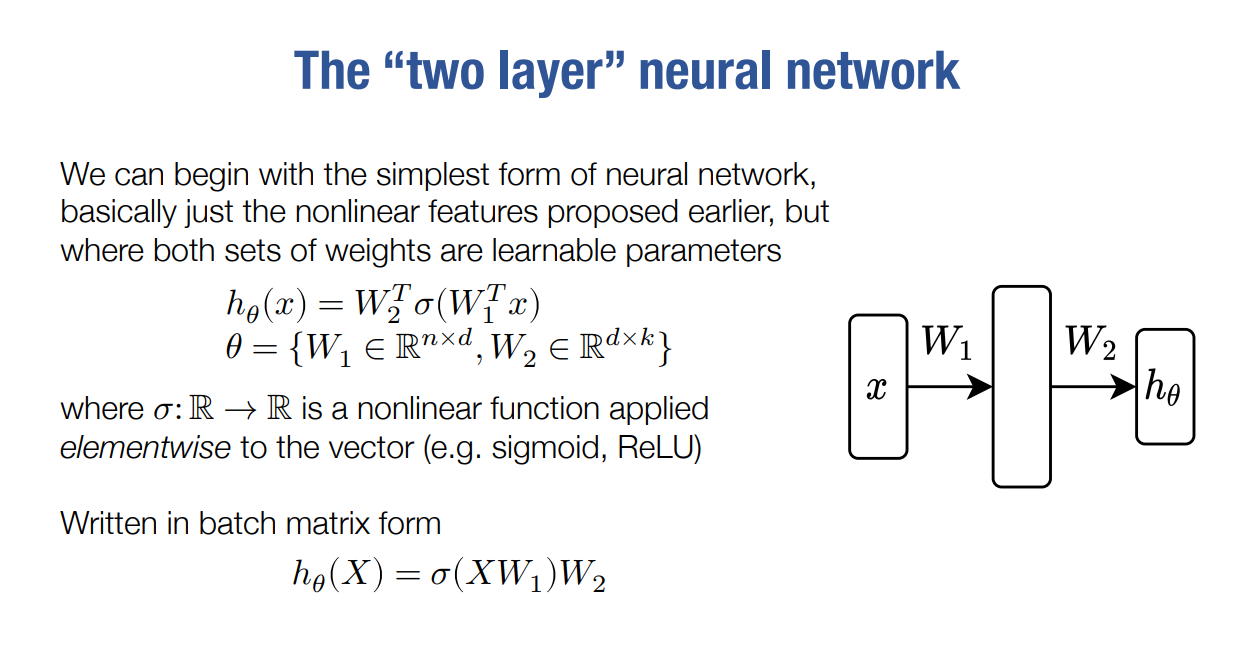
梯度下降求导
