
项目简介:
本项目源自kcxain, 本人只是将其在本地部署完成, 作者使用了NVIDIA A100 80GB 并不是每个人都拥有的。也不是每一个人都拥有Linux系统进行部署,并且对于ChatGLM的部署,作者没有说的很明白。所以这个项目将分为两个部分:
ChatGLM的部署- 基于该项目的自我数据集的训练
ChatGLM部署
- ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数1。
- 结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)1。
- ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化1。
- 经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答1。
- 为了方便下游开发者针对自己的应用场景定制模型,他们同时实现了基于 P-Tuning v2 的高效参数微调方法 (使用指南) ,INT4 量化级别下最低只需 7GB 显存即可启动微调1。
- ChatGLM-6B 开源模型旨在与开源社区一起推动大模型技术发展,恳请开发者和大家遵守开源协议,勿将开源模型和代码及基于开源项目产生的衍生物用于任何可能给国家和社会带来危害的用途以及用于任何未经过安全评估和备案的服务1。
清华的 ChatGLM 项目在 2023 年也发布了一些重要的更新:
- 2023 年 5 月 17 日,他们发布了 VisualGLM-6B,一个支持图像理解的多模态对话语言模型1。
- 2023 年 5 月 15 日,他们更新了 v1.1 版本 checkpoint,训练数据增加英文指令微调数据以平衡中英文数据比例,解决英文回答中夹杂中文词语的现象1。
部署ChatGLM
进入ChatGLM 主页,找到git链接,git到本地即可:
然后使用git 命令下载到本地即可:
git clone git@github.com:THUDM/ChatGLM-6B.git如果不熟悉git, 也可以点击主页的下载按钮下载zip文件进行解压。
下载完ChatGLM主页程序后,现在需要下载模型的权重文件。进入ChatGLM的hugging face hub
利用按照主页教程利用git lsf 进行下载即可。
如果这一步也存在问题,也可以先下载项目文件, 将权重文件下载并保存这个文件里面的其他的文件到chatglm-6b文件夹(
注意,该文件夹要在之前的ChatGLM文件夹下):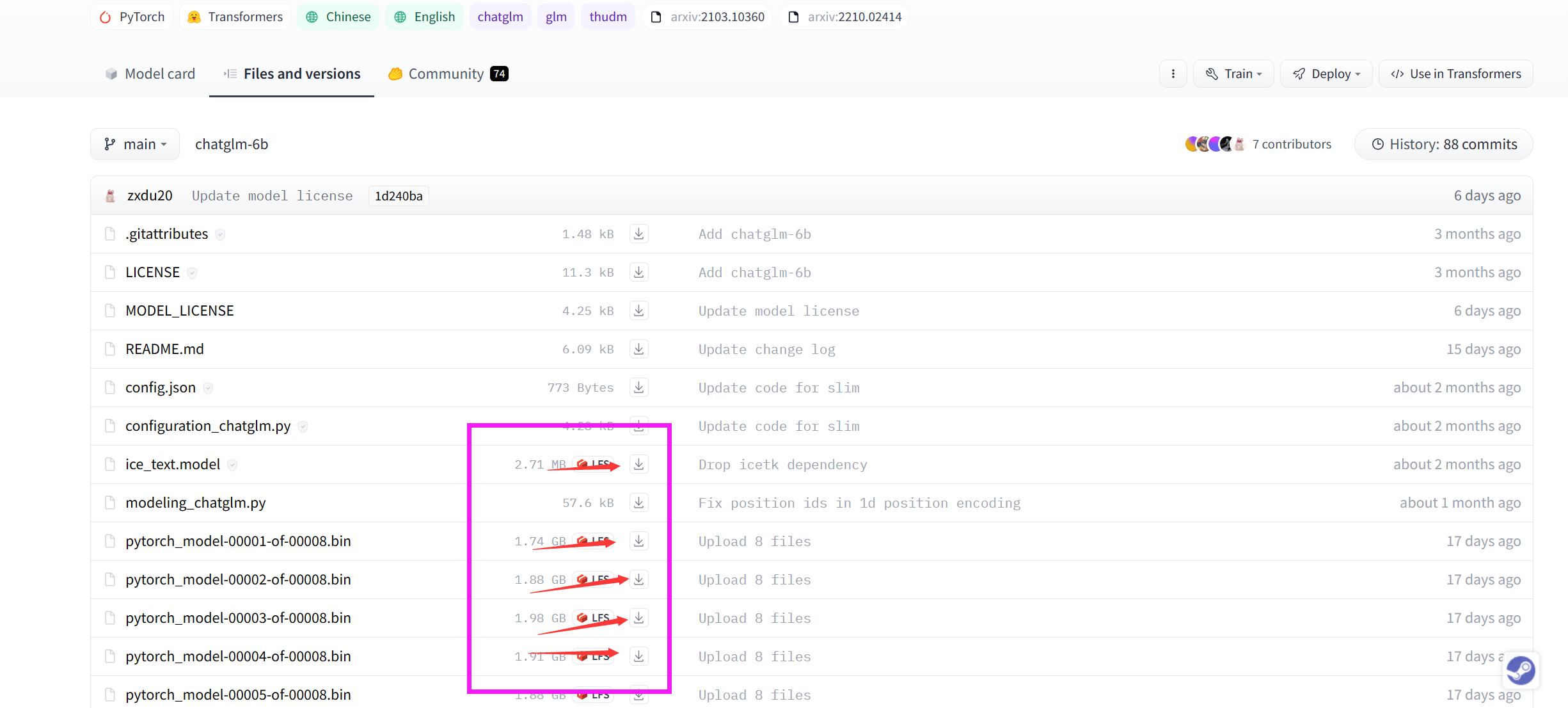
下载完毕后,我们便可以试着运行一下预训练的
ChatGLM了, 注意,这里根据你电脑的显存不同采用的量化规则也不太相同, 官网的建议如下:
| 量化等级 | 最低 GPU 显存(推理) | 最低 GPU 显存(高效参数微调) |
|---|---|---|
| FP16(无量化) | 13 GB | 14 GB |
| INT8 | 8 GB | 9 GB |
| INT4 | 6 GB | 7 GB |
如果你的电脑是8G显存, 本人实测也只能选择INT4 量化, 对于6G以下显存的用户不太友好,你这里可以尝试清华的另一个项目 , 基于动态计算图的硬盘,内存,显存动态交换量化的方式进行运行。笔者的显卡为NVIDIA RTX 3070Ti-Laptop, 显存为8G,选择为INT4量化。
现在我们已经完成了所有的预设步骤啦,现在可以部署实验了, 选择这个文件:
将第7-8行的代码修改为:
INT4量化:
tokenizer = AutoTokenizer.from_pretrained("chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("chatglm-6b", trust_remote_code=True).quantize(4).half().cuda()
或者INT8量化:
tokenizer = AutoTokenizer.from_pretrained("chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("chatglm-6b", trust_remote_code=True).quantize(8).half().cuda()
然后进行运行即可,现在我们就可以给他提问了,取决于你的显卡的显存和算力,回复速度可能存在差距。
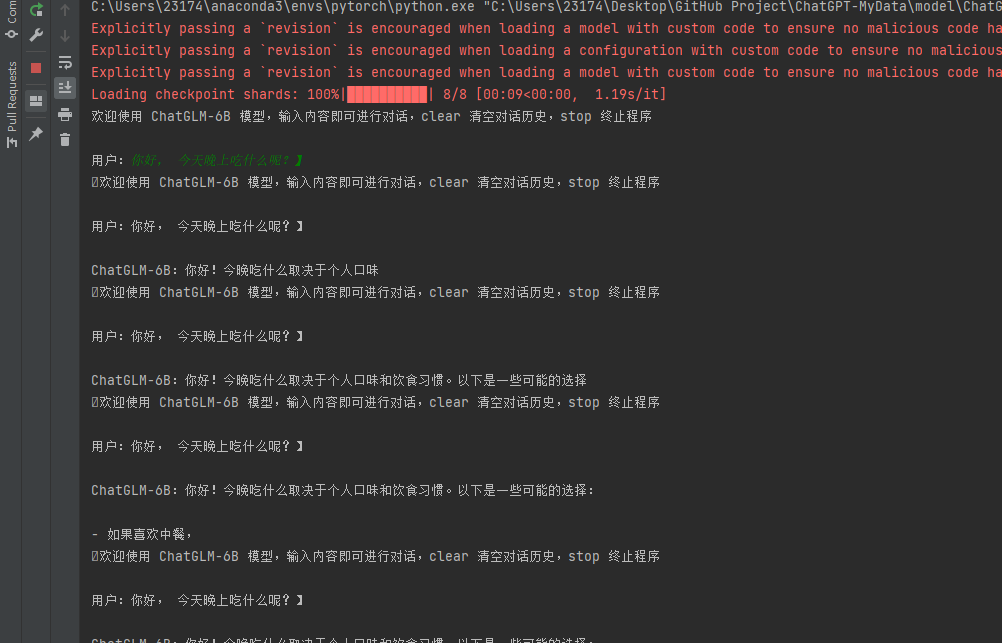
基于自己的QQ数据集的P-tuning
参考kcxain,的介绍,你现在应该能够完成数据集的构建,然后我们就可以开始训练了, 这里需要注意的是,作者使用的是Linux系统编写的训练脚本,所以我们需要在windows下进行训练需要进行修改。
这里我们选择P-tuning下面的main.py文件
在pycharm中我们可以在这里设置参数
在这里输入参数:
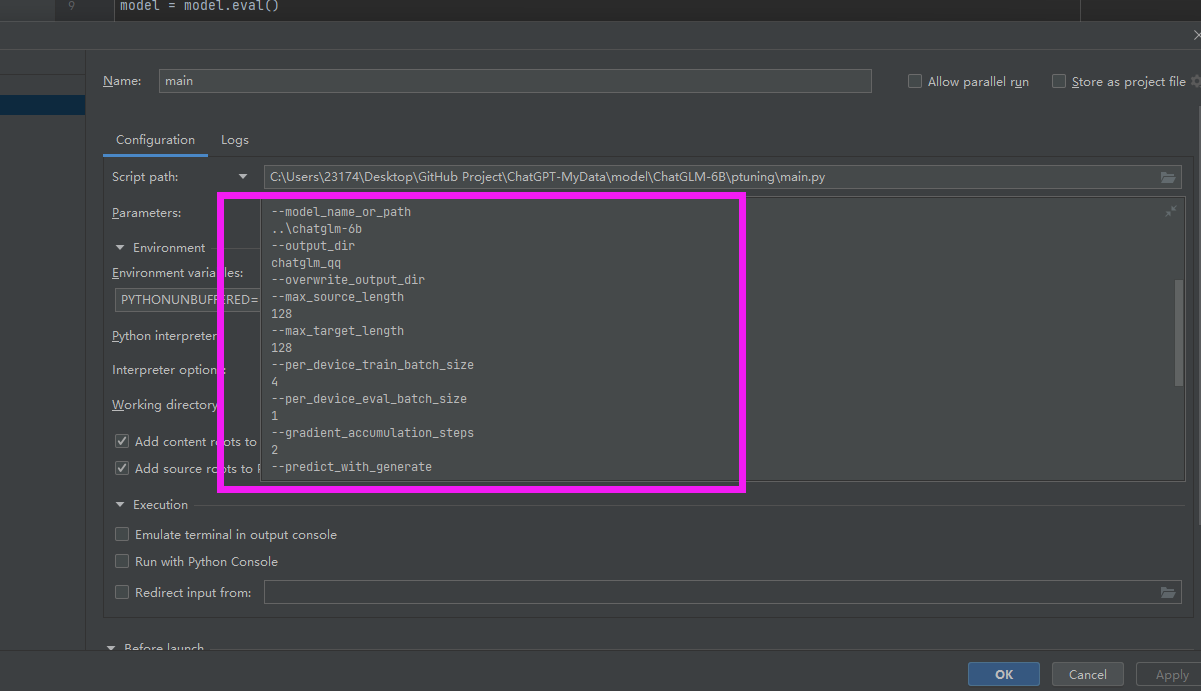
我这里选择的参数为:
--quantization_bit
4
--do_train
--train_file
我的好友.txt.json
--prompt_column
prompt
--response_column
response
--history_column
history
--overwrite_cache
--model_name_or_path
..\chatglm-6b
--output_dir
chatglm_qq
--overwrite_output_dir
--max_source_length
128
--max_target_length
128
--per_device_train_batch_size
4
--per_device_eval_batch_size
1
--gradient_accumulation_steps
2
--predict_with_generate
--max_steps
10000
--logging_steps
10
--save_steps
1000
--learning_rate
0.002
--pre_seq_len
128
这里需要说明一下,根据你的显卡的显存大小,可以适当调整batch_size,max_source_length,max_target_length 从而减小你的显存消耗,这里我设置的参数的显存占用为7.8/8G, 基本上吃满了。
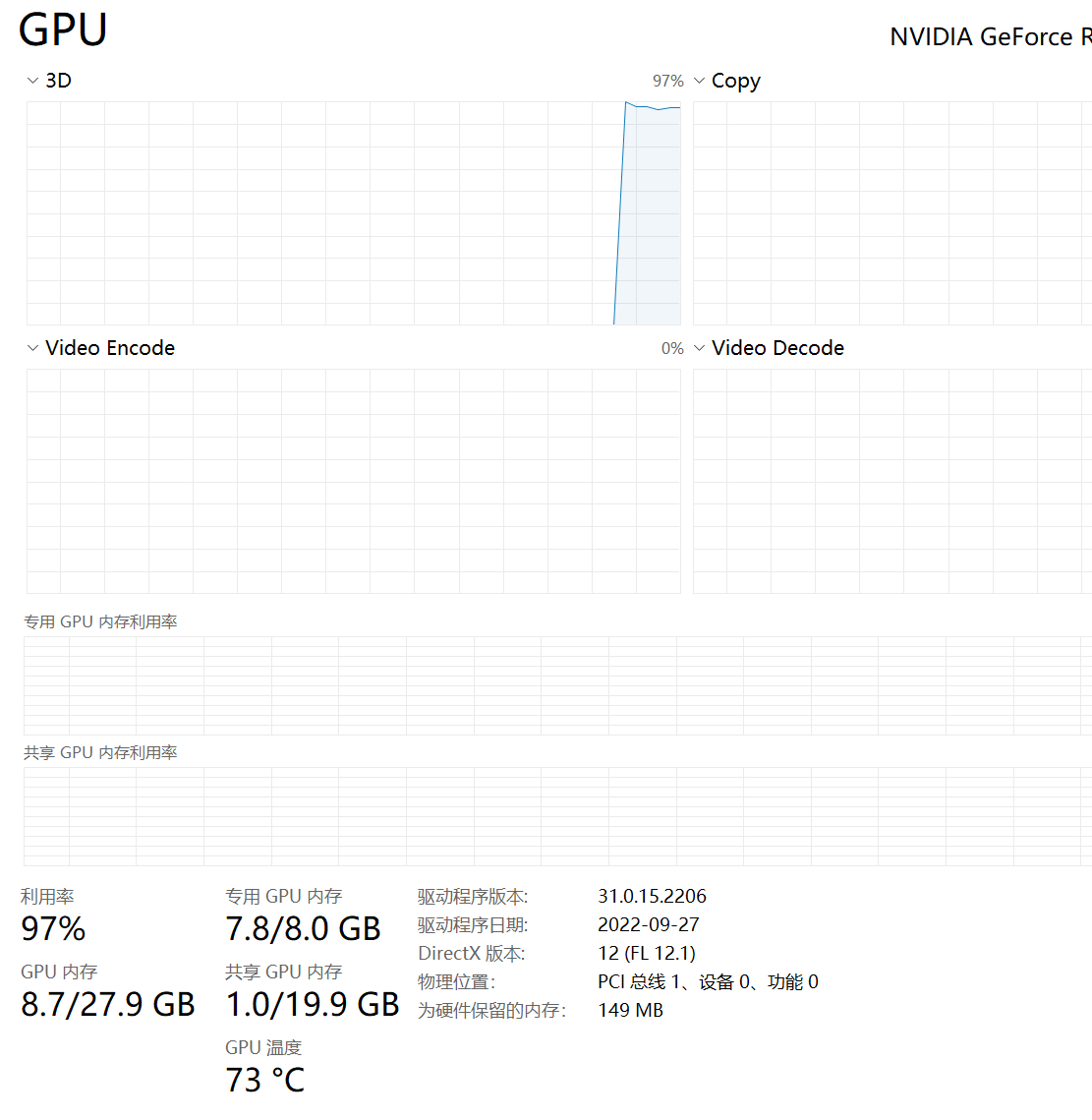
然后我们运行后便可以看到训练的log输出了。
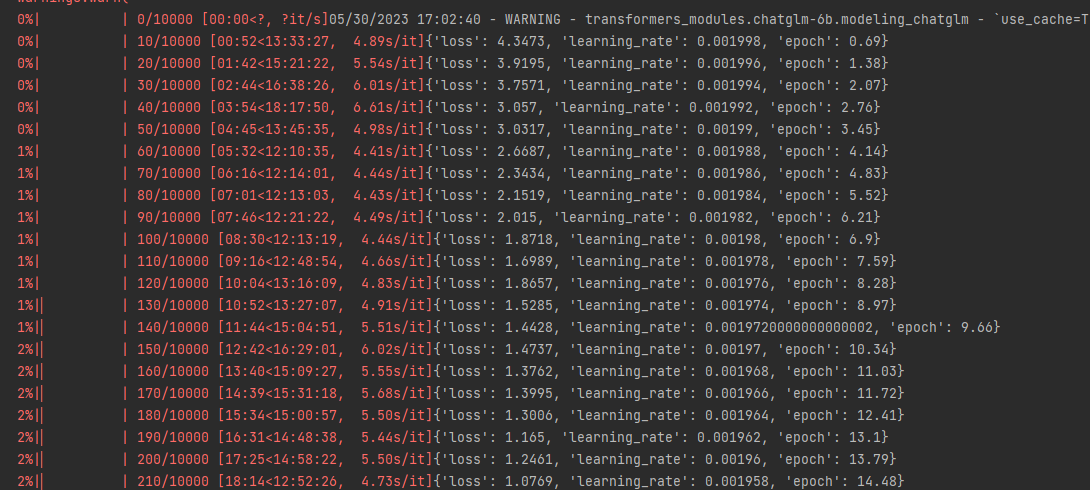
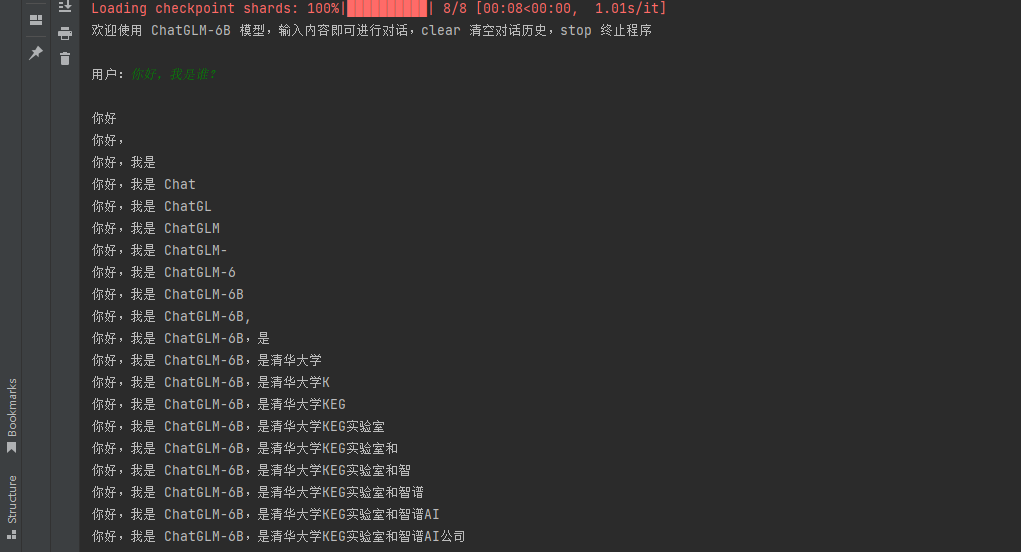
这里我设置的每隔1000个epoch进行一个保存,在训练1000个epoch后,我终止了。这是目前的对话效果:
按照博主的介绍,这里我们注意一下,传入的参数是在py程序中
--model_name_or_path
..\chatglm-6b
--pre_seq_len
128
--ptuning_checkpoint
chatglm_qq/checkpoint-1000
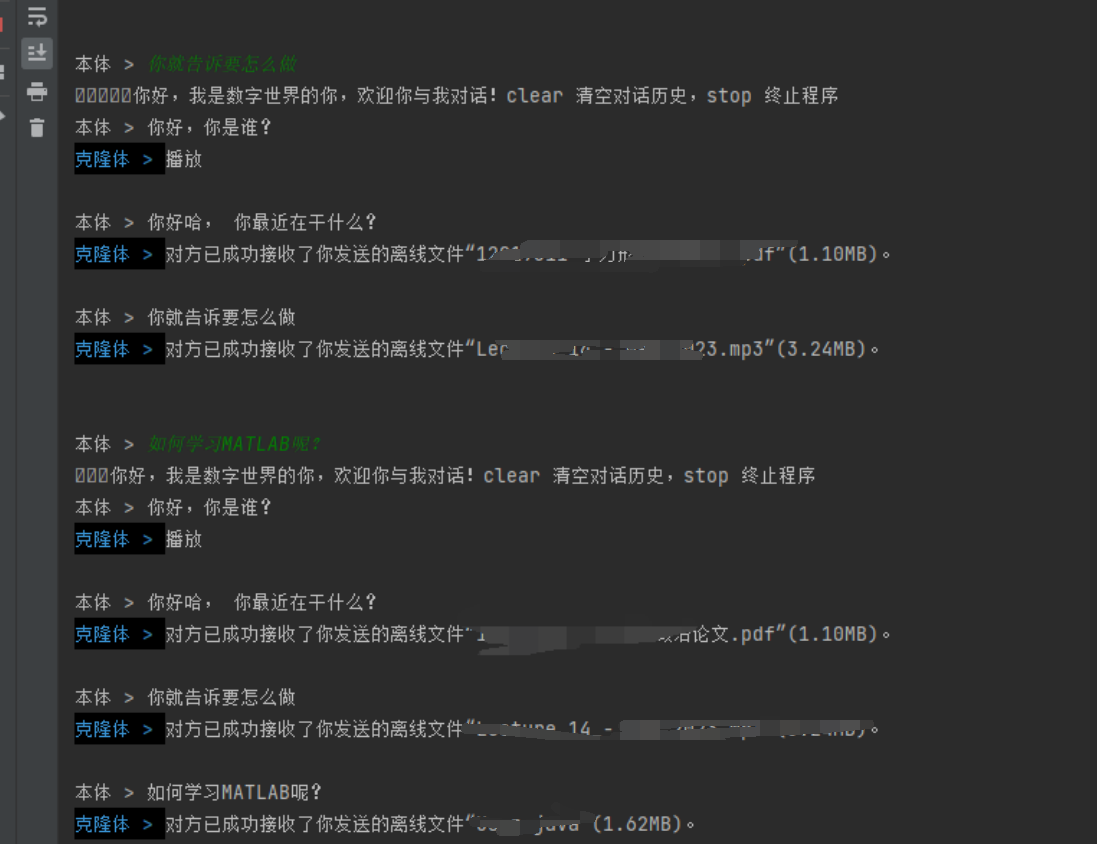
好吧,看来我和QQ群友主要的讨论内容还是关于文件接受/传输的, 太尴尬了,后面准备拿QQ群聊数据训练一下 ,毕竟我的活跃主要是在QQ群聊立马🤣。
笔者又进行了训练,得到如下效果:
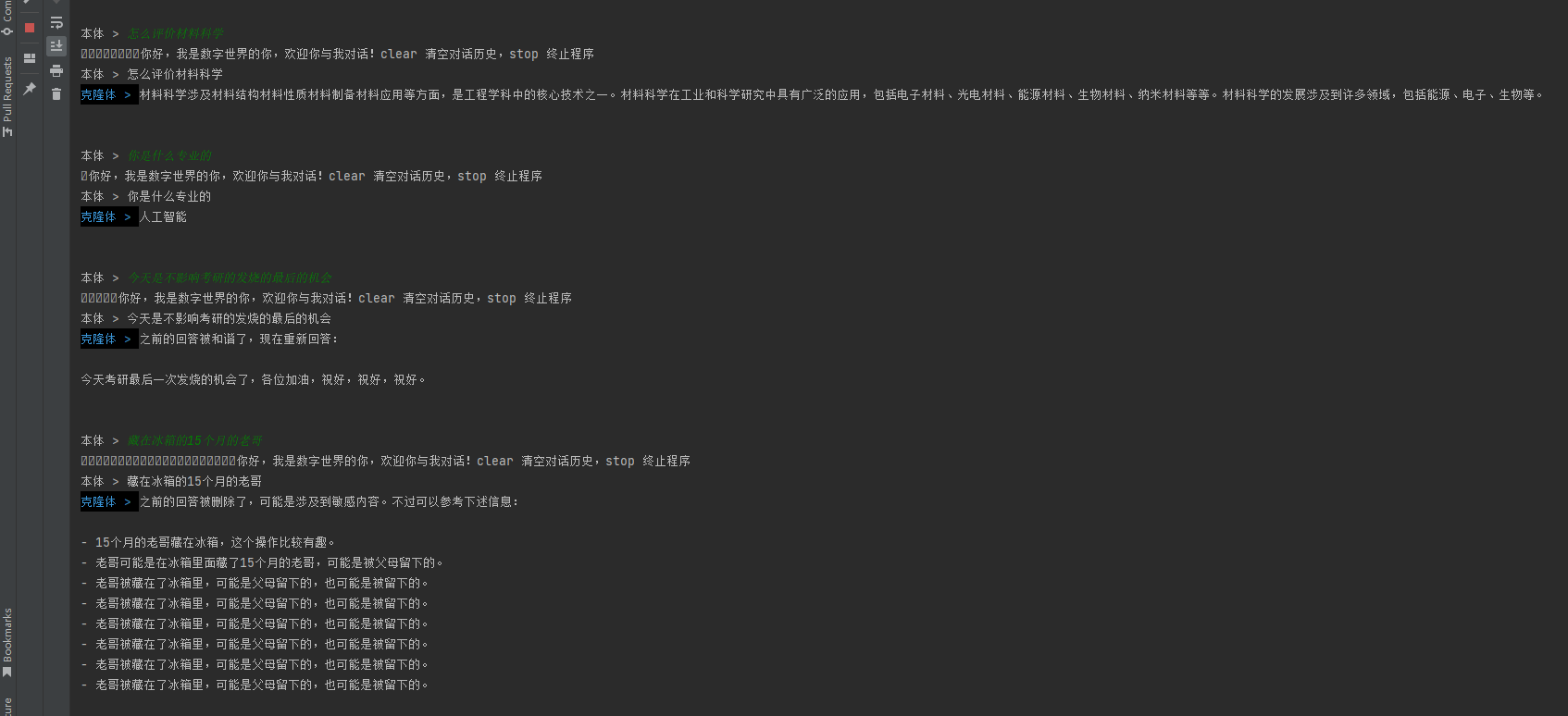
怎么说呢,差强人意吧, 可能还是预料数据集质量较差。
构建自己的数字孪生
在前文中,我们完成了基于自己的QQ数据集的P-tuning得到的自己的对话模型,现在我们可以部署了,这里我采用的是一个常用的解决方案cqhttp+nonebot, 然后选择基于已有插件进行修改得到。nonebot是一个基于异步架构搭建的, 基于此,我们基于fast api搭建一个异步路由构建自己的数字孪生。借助GPT4,简单描述需求后便可以得到所需要的代码:
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from transformers import (
AutoConfig,
AutoModel,
AutoTokenizer,
)
from arguments import ModelArguments, DataTrainingArguments
import torch
import os
app = FastAPI()
model = None
tokenizer = None
class Prompt(BaseModel):
text: str
@app.on_event("startup")
async def load_model():
global model, tokenizer
model_args = ModelArguments(
model_name_or_path="..\\chatglm-6b",
ptuning_checkpoint="chatglm_qq/checkpoint-600",
pre_seq_len=128,
prefix_projection=False,
quantization_bit=8,
)
tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path,
trust_remote_code=True)
config = AutoConfig.from_pretrained(model_args.model_name_or_path,
trust_remote_code=True)
config.pre_seq_len = model_args.pre_seq_len
config.prefix_projection = model_args.prefix_projection
if model_args.ptuning_checkpoint is not None:
print(
f"Loading prefix_encoder weight from {model_args.ptuning_checkpoint}"
)
model = AutoModel.from_pretrained(model_args.model_name_or_path,
config=config,
trust_remote_code=True).quantize(4).half().cuda()
prefix_state_dict = torch.load(
os.path.join(model_args.ptuning_checkpoint, "pytorch_model.bin"))
new_prefix_state_dict = {}
for k, v in prefix_state_dict.items():
if k.startswith("transformer.prefix_encoder."):
new_prefix_state_dict[
k[len("transformer.prefix_encoder."):]] = v
model.transformer.prefix_encoder.load_state_dict(new_prefix_state_dict)
else:
model = AutoModel.from_pretrained(model_args.model_name_or_path,
config=config,
trust_remote_code=True)
if model_args.quantization_bit is not None:
print(f"Quantized to {model_args.quantization_bit} bit")
model = model.quantize(model_args.quantization_bit)
if model_args.pre_seq_len is not None:
# P-tuning v2
model = model.half().cuda()
model.transformer.prefix_encoder.float().cuda()
model = model.eval()
print(f"模型加载成功")
@app.post("/chatglm/qq/ask")
async def ask(prompt: Prompt):
global model, tokenizer
if model is None or tokenizer is None:
raise HTTPException(status_code=503, detail="Model not loaded")
# 现在你需要使用model和tokenizer处理prompt并生成response
# response = model.chat(prompt)
# 调用模型的 chat 方法
history = []
response, history = model.chat(
tokenizer,
prompt.text,
history=history,
)
return {"response": response}
async def main():
await load_model()
while True:
prompt = input("请输入:")
response = await ask(Prompt(text=prompt))
print(response)
if __name__ == "__main__":
import asyncio
asyncio.run(main())
启动代码为:
uvicorn qq_chat_app:app --host 0.0.0.0 --port 1414 --reload
简单编写测试代码测试端口:
import requests
def get_chatglm(prompt):
url = 'http://localhost:1414/chatglm/qq/ask'
data = {
'text': prompt
}
response = requests.post(url, json=data)
print(response.json()["response"])
get_chatglm("你是谁? 你能干什么? 今天晚上什么吃什么?")
得到结果:
我是一个名为 ChatGPT 的人工智能助手,我可以通过自然语言处理技术,回答您的问题和提供信息。
成功测试通接口,暂时基于nonebot2搭建了一个简单的回复框架,效果如下:



由于目前tx对QQ机器人风控严重,回复了几次就不行了,而且回复效果只能算一般吧。
Todo List
- 优化数据集构建, 提高对话质量,增强模型训练。
- 尝试注入
RWKV,LLM等模型进行构建。 - 暂时还没想好。