OpenAI_New_API_Capacities
2023/11/27
这个博客主要是关于如何利用
OpenAI官方新推出的API的功能。 关于最新功能的介绍。对应的项目链接可以参考GitHub链接。
语言框架: python
加载过慢请开启缓存 浏览器默认开启

这个博客主要是关于如何利用
OpenAI官方新推出的API的功能。 关于最新功能的介绍。对应的项目链接可以参考GitHub链接。
语言框架: python
This blog tells you mainly about how to build your first scrapy project.
在开发Python项目的时候,我们常常需要导出一个Python项目的依赖文件为
requirements.txt, 很多人尝试都是一个个逐一查找依赖,其实有库可以帮我们做这个。下面介绍的这个库为
pipreqs。
This blog tells how you could build your own first
electron appfrom scratch.
This blog tells how you could set up your custom
loggingmodule in your Fast API app.
| 文章题目 | 本地文件位置 | 年份 | 发表刊物 | 解决问题 | 方法 | 关键创新点 | 数据集 | 代码 | 实现难易程度 |
|---|---|---|---|---|---|---|---|---|---|
| Scalable Gradients for Stochastic Differential Equations | duval23a.pdf | 2023 | JMLR | 1. 通过Stochastic Frame Averaging变换保留原子坐标的投影对称性,数据处理值得借鉴。 2. 然后结合GNN和MLP构建了神经网络,这部分并未很突出。 3. 取得较好的表现。 |
Stochastic Frame Averaging: PCA降维 | 对称保持的数据增强:研究者提出了一种新方法,使得GNN在处理数据时可以保持其原始的对称性。 FAENet:这是研究者开发的一个新的GNN模型。它的特点是可以自由地处理原子之间的位置关系,同时确保数据的对称性不被破坏。 FAENet分析:研究者测试了他们的新方法和新模型在几个材料科学数据集上的性能,并发现它比以前的方法更好。 | OC20 dataset (S2EF, IS2RE),(QM9, QM7-X) | 1.FAENet: Frame Averaging Equivariant GNN for Materials modeling — faenet documentation 2. vict0rsch/faenet (github.com) | 使用较为容易,修改需要熟悉代码, 估计熟悉代码需要两周。 |
| Flashlight: Scalable Link Prediction With Effective Decoders | wang22d.pdf | 2022 | PMLR | 比较远的原子在多路信息传递的信息丢失和区分键角不同的结构。 | 1. frame construction 2. coordination projection 3.frame-frame projection | even ordinary GNN can encode molecule injectively and thus reach maximum expressivity with coordinate projection and frame-frame projection. | MD17 | GraphPKU/GNN-LF (github.com) | 代码结果较为简单,估计一周可以熟悉并复现。 |
| Deep Potential Molecular Dynamics: a scalable model with the accuracy of quantum mechanics End-to-end Symmetry Preserving Inter-atomic Potential Energy Model for Finite and Extended Systems |
NeurIPS | 2017/2018 | PRL/NeurIPS | Molecular modeling, Inter-atomic potential energy surface modeling | Deep Potential - Smooth Edition (DeepPot-SE) | Extensive, continuously differentiable, linear scalability, symmetry preservation | 各种系统,包括高熵合金(基于DFT数据, 阿里云数据已过期) | DeePMD-kit (github.com) | 基于TensorFlow实现,使用较为方便,对其进行修改比较困难,不太熟悉TensorFlow框架。 |
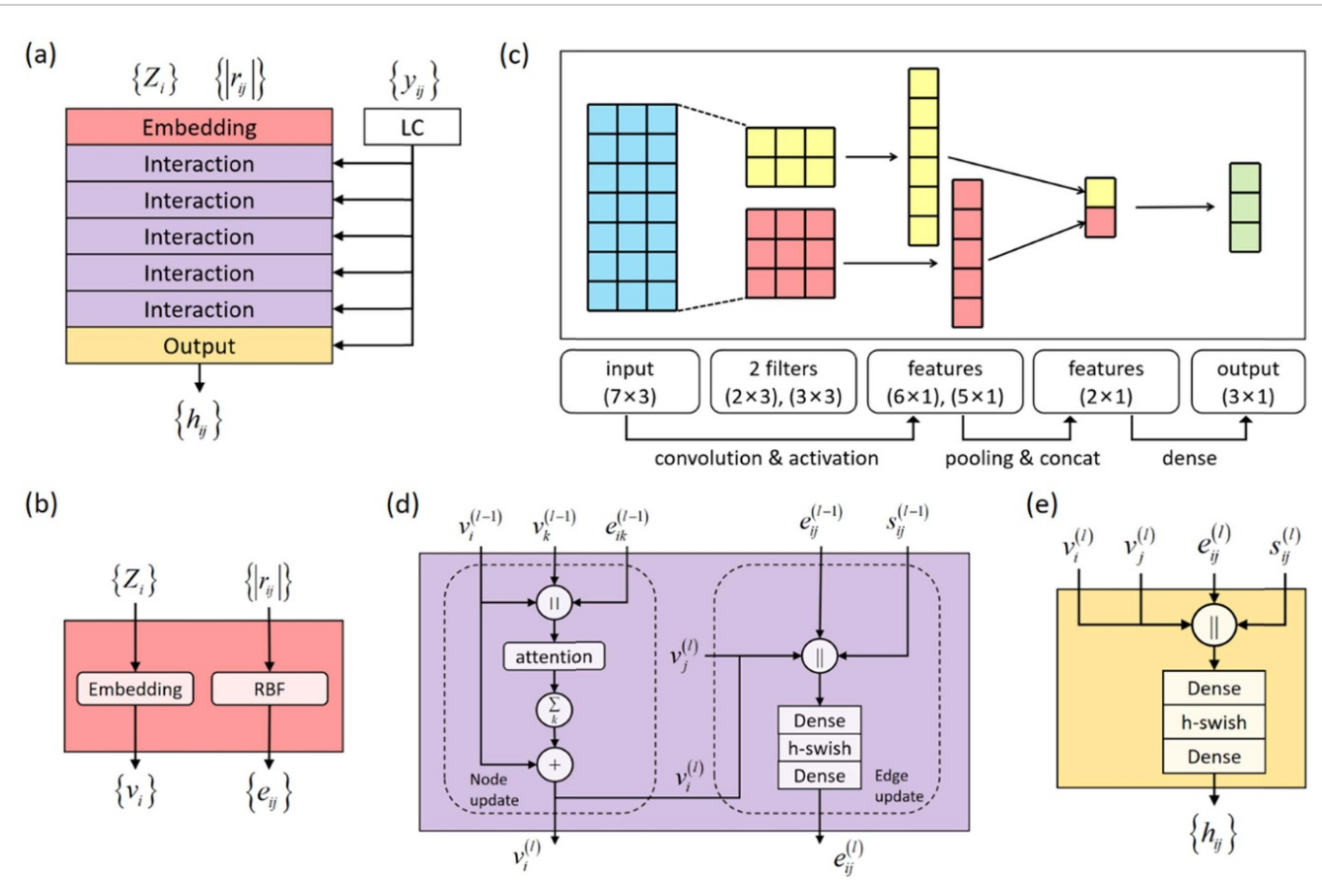
| Efficient determination of the Hamiltonian and electronic properties using graph neural network with complete local coordinates | Su_2023_ | 2023 | MLST(machine learning: Science and Technology) | 使用图神经网络(Graph Neural Network, GNN)架构和LC变换(LC transformation)构建原子体系与哈密顿量(由下面的hopping parameter给出)的关系,$h_{i \alpha, j \beta}^{\left(\mathbf{R}n\right)}=\left\langle\phi{i \alpha}\left(\mathbf{r}-\boldsymbol{\tau}_i\right) | \hat{H} | \phi_{j \beta}\left(\mathbf{r}-\boldsymbol{\tau}_j-\mathbf{R}_n\right)\right\rangle$ | LC变换(LC transformation), GNN | 使用哈密顿量作为回归的lable。 |
Self Made dataset:Graphene and , zincblend SiGe |
| Cormorant:协变分子神经网络 | PDF链接 | 2019 | NeurIPS | 开发名为Cormorant的神经网络架构,专为学习复杂多体物理系统的行为和性质。 2. 应用于分子系统,学习用于分子动力学模拟的原子势能面及由密度泛函理论计算的分子基态特性。 3. 确保网络的旋转不变性,增加网络的表达力。 | 输入特征化网络,只对原子电荷/身份和相对位置的标量函数进行操作。 2. 协变激活网络,每个激活都是$\mathrm{SO(3)}$-向量类型。 3. 顶部的旋转不变网络,从激活构造标量,用于预测回归目标。 | Clebsch-Gordan非线性,实现激活中每个自由度的完全交互。 2. 确保网络的旋转和平移不变性,神经元实现的操作直接由已知的物理相互作用的形式激发。 3. 网络激活以球形张量形式(SO(3)–向量)表示,结合Clebsch–Gordan乘积和可学习权重的混合,所有操作都是协变操作。 | MD-17数据集(学习分子力场和势能表面), QM-9数据集(学习一组分子的基态性质, 前文使用的数据) | github链接: | 重现代码较为容易,代码实现设计较为复杂的物理数学原理,修改可能比较困难。 |
| Do Transformers Really Perform Bad for Graph Representation? | 探讨Transformer在图表示学习中的表现,并提出Graphormer来提升性能 | NeurIPS | Graphormer的提出,通过结构编码方法来优化Transformer对图结构数据的处理。 | . 中心性编码:使用度中心性来为每个节点分配嵌入向量。 2. 空间编码:衡量节点间的最短路径距离,将其作为偏置项加到注意力矩阵中。 3. 边编码:计算边特征与可学习嵌入的点积的平均值,作为偏置项加到注意力模块中。 | OGB Large-Scale Challenge (OGB-LSC) 中的 MAG240M, WikiKG90M, PCQM4M数据集 2. OGBG-MolPCBA, OGBG-MolHIV, ZINC(sub-set) | Graphormer on GitHub | 具有较为完备的代码和教程,复现不困难,进行修改难度需要进一步评估。 | ||
| E(3)-equivariant graph neural networks for data-efficient and accurate interatomic potentials | 链接 | 2022 | Nature Communications | 1. 加速分子动力学模拟的深度学习原子势方法的引入。2. 提高了分子和材料集合的准确性,同时展现了显著的数据效率。 | **Neural Equivariant Interatomic Potentials (NequIP)**:E(3)-equivariant neural network 方法用于从ab-initio计算中学习分子动力学模拟的原子势。 | E(3)-equivariant卷积:与大多数仅在标量上作用的当前对称感知模型不同,NequIP采用E(3)-equivariant卷积来处理几何张量的交互,从而更丰富、更真实地表示原子环境。 | 1. MD-17 Dataset 2. QM9 Dataset 3. ISO17 Dataset | http://github.com/mir-group/nequip | 有较为完备的文档和项目以及实现,上手起来应该比较容易。 |
OC20 Dataset (S2EF, IS2RE):
QM9 Dataset:
QM7-X Dataset:
MD17 Dataset:
The MD17 (Molecular Dynamics 17) Dataset was introduced by Chmiela et al., focusing on energies and forces for molecular dynamics trajectories of eight small organic molecules.
The dataset has been used for the development and evaluation of machine-learned potential energy surfaces (PES). Each molecule in the database comprises tens of thousands of energies and forces obtained from DFT (Density Functional Theory) direct dynamics at 500 K. Notable examples of molecules included are ethanol, malonaldehyde, and glycine (source). -
A revised version of the dataset, known as rMD17, was introduced by Anders S. Christensen and O. Anatole von Lilienfeld in 2020. This version recalculated the energies and forces at a different level of theory, aiming to address the role of gradients in machine learning of molecular energies and forces. Moreover, a third version of the dataset was introduced, containing fewer molecules computed at the CCSD (T) (Coupled Cluster with Single and Double excitations) level of theory (source).
The original MD17 dataset contained numerical noise, which was noted and addressed in the revised version to ensure accuracy in machine learning benchmarks (source).
Graphene :
We perform molecular dynamics simulation of a 6 × 6 × 1 graphene structure for 5 ps to generate the dataset. sample 500 structures as the training set and the other 500 structures as the validation set
zincblend SiGe:
The SiGe random alloy dataset is generated by randomly occupying the zinc-blende lattice sites with the Si or Ge atoms. The number of possible combinations in a supercell with N sites is given by the combinatorial number C(N,N/2), which could be incredibly large as the total atom number increases.
ISO17 Dataset:
Description: The ISO17 dataset, also known as “ISO17 - MD Trajectories of C7O2H10 with total energies and atomic forces,” is derived from a set of molecules from the QM9 dataset with a fixed composition of atoms (C7O2H10) in various chemically valid structures. These molecules were selected from the largest set of isomers in the QM9 dataset[^1^].
Composition: The dataset contains:
X (7165 x 23 x 23): Inputs (Coulomb matrices)
T (7165): Labels (atomization energies)
P (5 x 1433): Splits for cross-validation[^2^]
Benchmark for Molecular Dynamics: ISO17 is a benchmark dataset for molecular dynamics of C7O2H10 isomers, including molecular forces[^3^].
Extension of Isomer MD Data: The dataset is an extension of the isomer MD data used in prior research[^4^].
References and Further Reading: - Quantum-Machine.org: Datasets - SchNetPack Documentation - kgcnn Documentation
指的是欧几里得空间中的刚体变换(或称为欧几里得变换)。这种变换在三维空间中保持距离和角度不变。具体来说,( E(3) ) 变换由以下两部分组成:
旋转:这是一个保持原点不变的变换,它可以使物体绕某个轴旋转。
平移:这是一个将物体从一个位置移动到另一个位置的变换,而不改变物体的方向或形状。
This includes translations, rotations, and reflections. An E(3)-equivariant neural network is designed to respect these symmetries, meaning that its output will change appropriately with such transformations of the input data.
输入原子坐标,得到能量和受力的任务。
For Equivariance in neural neural network, that means the output of the neural network can be predicted when the input data is transformed, or to say the output is also given in the same transformed way as the input day or in a correlation way.
FAENet: Frame Averaging Equivariant GNN for Materials Modeling
该论文通过引入SFA和FAENet,提出了一种新的视角和方法,以数据投影的方式保持对称性,而不是通过架构约束。这些方法旨在创建表达能力强、健壮且计算上可扩展的模型,以便进行大规模的材料属性评估和预测。在多个数据集上的实证验证表明,这些方法在精度和计算可扩展性方面提供了优越的权衡。
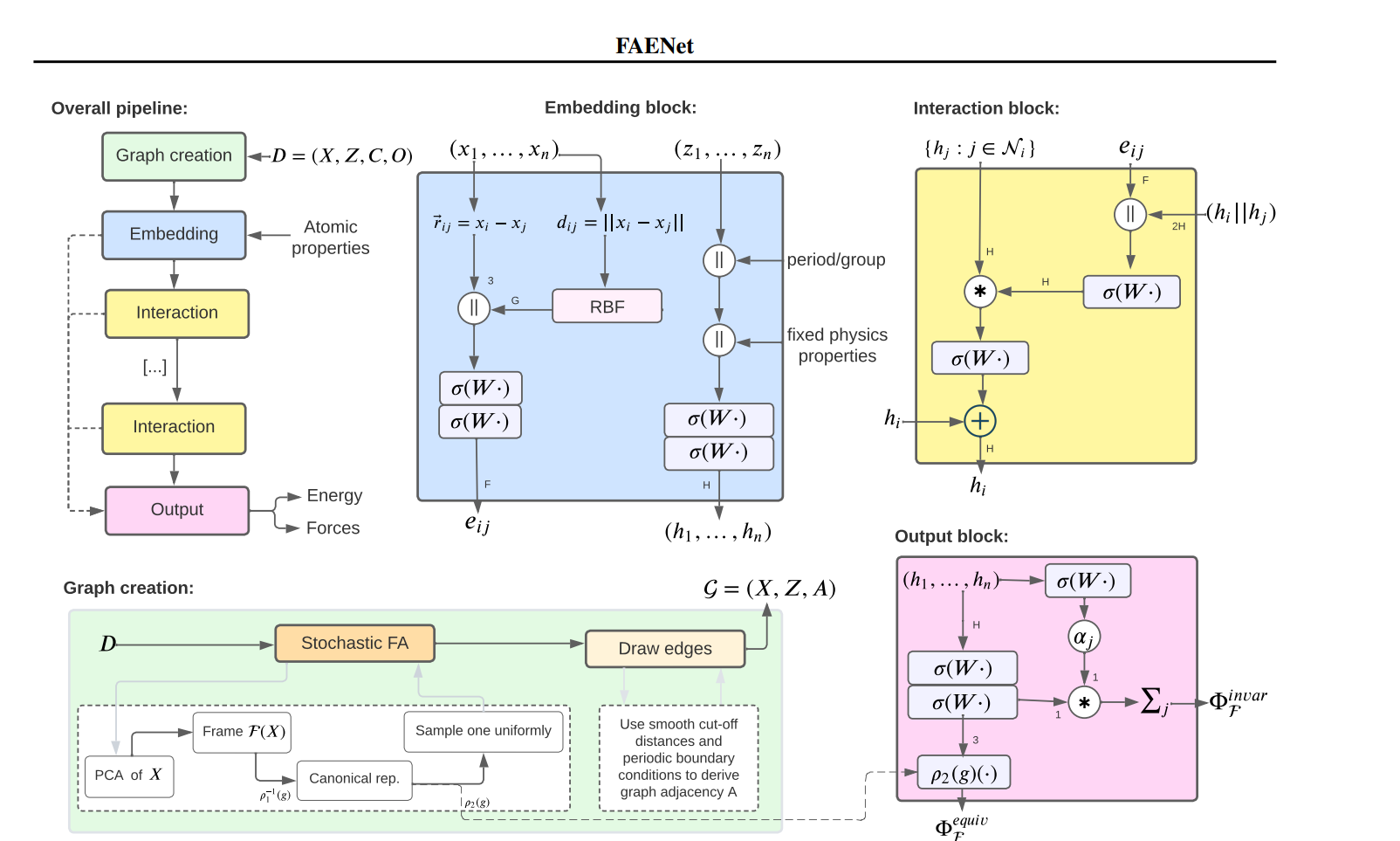
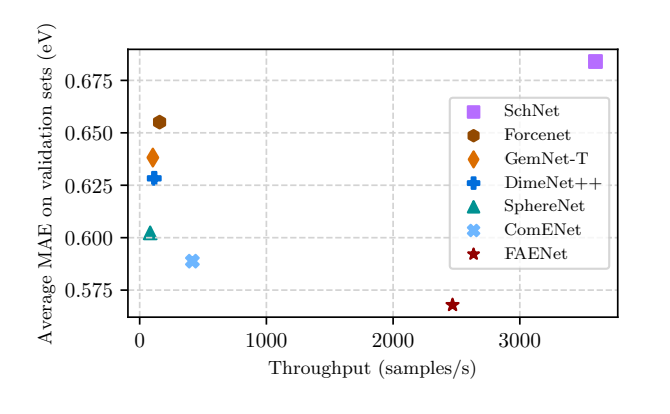
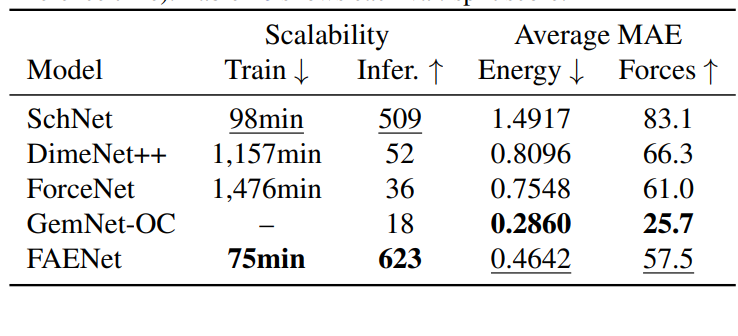
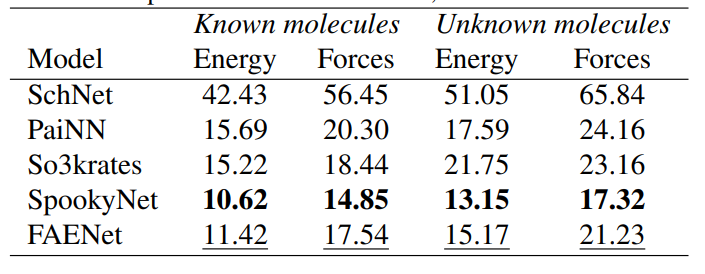
Graph Neural Network with Local Frame for Molecular Potential Energy Surface
该论文通过引入GNN和局部帧方法,提出了一种新的方法来模拟分子PES,允许捕获几何信息并从GNN设计中解耦对称性要求。所提出的模型,GNN-LF,使用简单的GNN架构,但实现了最先进的准确性,并提供了与高效基线相比更高的可扩展性。作者通过实验提供了理论证明和方法的优越性能和可扩展性的演示。
我这里采用的是采用docker来启动mysql。
为了解决这个问题,你可以选择以下方法之一:
设置一个 root 密码:
docker run -e MYSQL_ROOT_PASSWORD=my-secret-pw mysql
允许空密码(不推荐在生产环境中使用):
docker run -e MYSQL_ALLOW_EMPTY_PASSWORD=yes mysql
使用随机密码:
docker run -e MYSQL_RANDOM_ROOT_PASSWORD=yes mysql
mysql

Ctrl + L 来清屏show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
4 rows in set (0.00 sec)
比如说要创建一个名叫game的数据库:
create database game;
DROP DATABASE game;
这个数据库名是大小写敏感·的。
创建表之前需要先use该database
USE game;
CREATE TABLE player (
id INT,
name VARCHAR(100),
level INT,
exp INT,
gold DECIMAL(10,2)
);
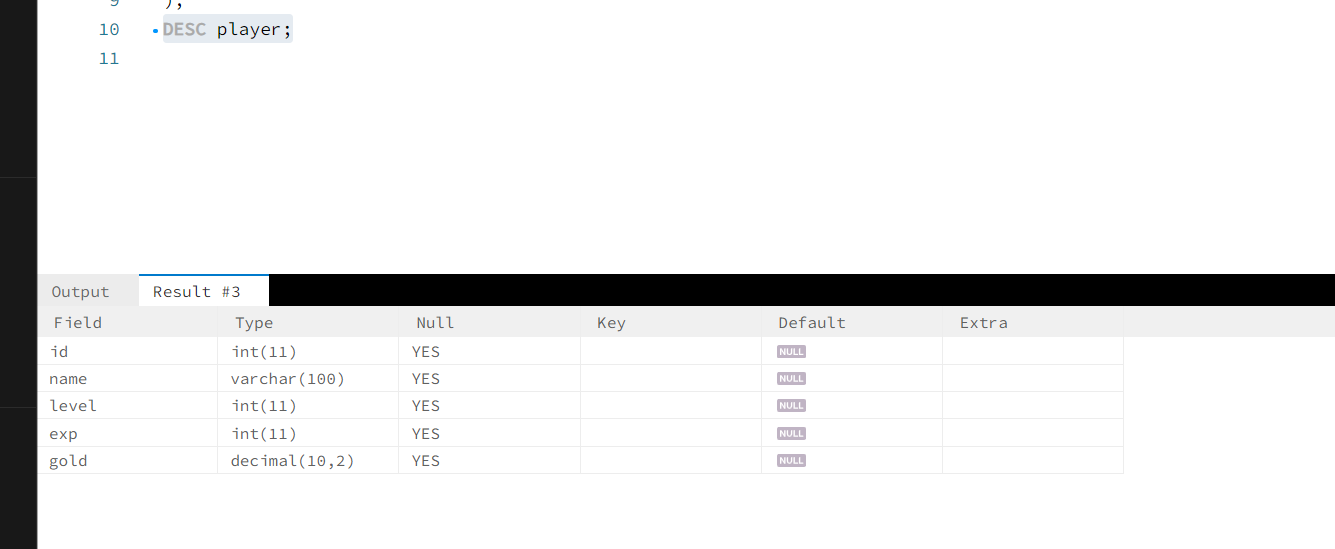
创建表结构。
DESC player;
修改表
添加新列
使用ALTER TABLE命令可以添加新列。例如,我们可以添加一个新列birth_date来存储玩家的生日:
ALTER TABLE player
ADD COLUMN birth_date DATE;
删除列
如果你想删除某个列,可以使用DROP COLUMN命令。例如,我们可以删除刚刚添加的birth_date列:
ALTER TABLE player
DROP COLUMN birth_date;
修改列
你可以使用MODIFY COLUMN命令来修改一个现有列的数据类型或其他属性。例如,我们可以将name列的长度从100修改为150:
ALTER TABLE player
MODIFY COLUMN name VARCHAR(150);
重命名列
如果你想重命名一个列,可以使用CHANGE COLUMN命令。例如,我们可以将exp列重命名为experience:
ALTER TABLE player
CHANGE COLUMN exp experience INT;
添加主键
为了确保id列中的每个值都是唯一的,我们可以将其设置为主键:
ALTER TABLE player
ADD PRIMARY KEY (id);
添加索引
为了提高查询速度,我们可以为某些列添加索引:
ALTER TABLE player
ADD INDEX idx_name (name);
INSERT INTO player (id, name, level, exp, gold) VALUES (1, "你好", 1, 1, 1);
SELECT * FROM player;
UPDATE player set level = 2 where name="你好";
SELECT * FROM player;
要导出MySQL数据库,您可以使用mysqldump工具。以下是一个基本的命令示例,用于导出整个数据库到一个.sql文件:
mysqldump -u [username] -p[password] [database_name] > [filename].sql
[username]:MySQL的用户名。[password]:该用户名的密码。注意,-p和密码之间没有空格。[database_name]:您想要导出的数据库名称。[filename].sql:您想要保存的文件名。要导入一个.sql文件到MySQL数据库,您可以使用以下命令:
mysql -u [username] -p[password] [database_name] < [filename].sql
参数的意义与上面的导出命令相同。
表连接是关系型数据库中的一个核心概念,它允许您从两个或多个表中基于某些相关列组合数据。以下是一些常见的连接类型:
假设我们有两个表:employees 和 departments。
employees 表:
| emp_id | emp_name | dept_id |
|---|---|---|
| 1 | Alice | 10 |
| 2 | Bob | 20 |
| 3 | Charlie | NULL |
departments 表:
| dept_id | dept_name |
|---|---|
| 10 | HR |
| 20 | Finance |
| 30 | Marketing |
SELECT emp_name, dept_name
FROM employees
INNER JOIN departments ON employees.dept_id = departments.dept_id;
结果:
| emp_name | dept_name |
|---|---|
| Alice | HR |
| Bob | Finance |
SELECT emp_name, dept_name
FROM employees
LEFT JOIN departments ON employees.dept_id = departments.dept_id;
结果:
| emp_name | dept_name |
|---|---|
| Alice | HR |
| Bob | Finance |
| Charlie | NULL |
SELECT emp_name, dept_name
FROM employees
RIGHT JOIN departments ON employees.dept_id = departments.dept_id;
结果:
| emp_name | dept_name |
|---|---|
| Alice | HR |
| Bob | Finance |
| NULL | Marketing |
由于MySQL不直接支持FULL JOIN,但如果它支持,结果将是:
| emp_name | dept_name |
|---|---|
| Alice | HR |
| Bob | Finance |
| Charlie | NULL |
| NULL | Marketing |
SELECT emp_name, dept_name
FROM employees
CROSS JOIN departments;
这会返回每个员工与每个部门的所有可能组合,总共9行。
希望这个例子更清晰地展示了不同连接类型的区别。